
AI is the new electricity.
You are the spark.
Get the latest AI news, courses, events, and insights from Andrew Ng and other AI leaders.
Join over 7 million people learning how to use and build AI
AI Courses and Specializations
Build a foundation of machine learning and AI skills, and understand how to apply them in the real world.
In Collaboration With
The largest weekly AI newsletter
What matters in AI right now
Apr 17, 2024
AI Agents With Low/No Code, Hallucinations Create Security Holes, Tuning for RAG Performance, GPT Store's Lax Moderation
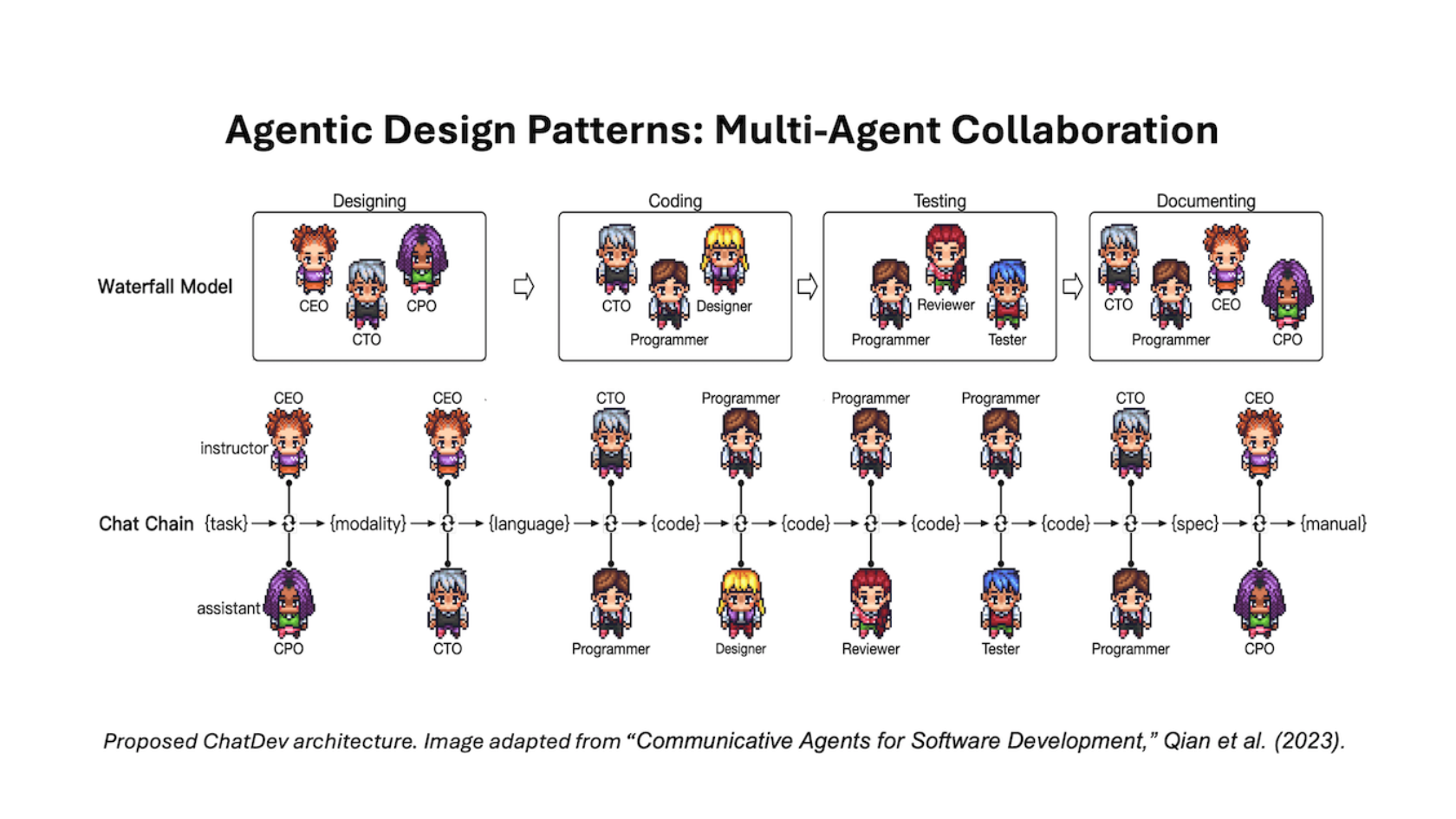
The Batch AI News and Insights: Multi-agent collaboration is the last of the four key AI agentic design patterns that I’ve described in recent letters. Given a complex task like writing software, a multi-agent approach would break...
Apr 10, 2024
Autonomous Coding Agents, Instability at Stability AI, Mamba Mania, What Users Do With GenAI
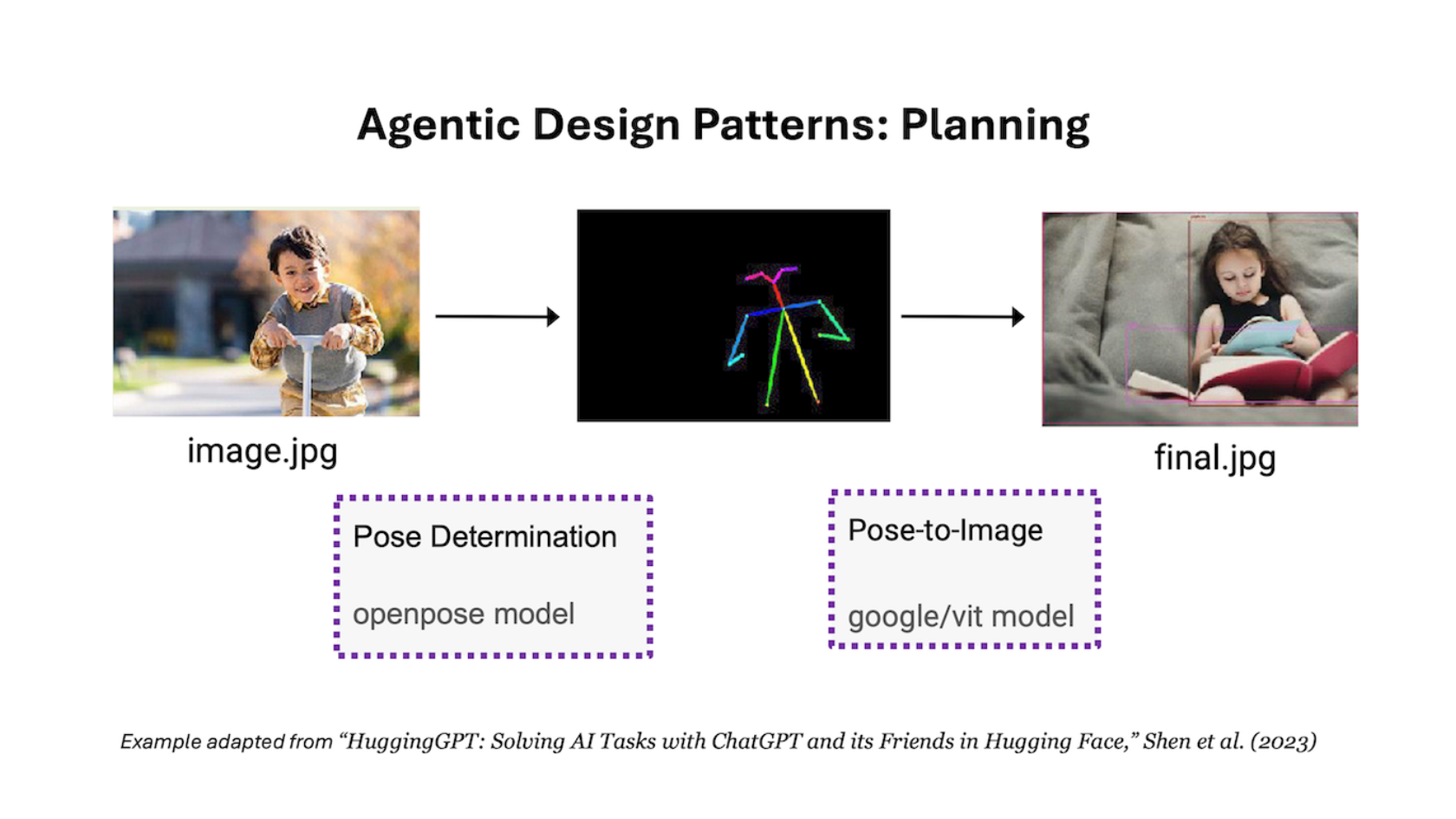
The Batch AI News and Insights: Planning is a key agentic AI design pattern in which we use a large language model (LLM) to autonomously decide on what sequence of steps to execute to accomplish a larger task.
Free Resources
Get Started with AI and Machine Learning

How to Build Your Career in AI
A practical roadmap to building your career in AI from AI pioneer Andrew Ng

Machine Learning Yearning
An introductory book about developing ML algorithms.

A Complete Guide to Natural Language Processing
A comprehensive guide covering all you need to know about NLP.
