
Dear friends,
If you haven’t already, I encourage you to experiment with using AI agents not just to chat but to actually do work for you on your desktop. Desktop agents not only chat with you but also read and edit local files, read/send messages, and provide scheduled deliverables like a daily news summary. While there's nothing wrong with copy-pasting output from web-based chatbots to a desktop or dragging and dropping files into chatbots to give them context, desktop agents can gain context more efficiently as well as take actions directly.
The main way such an agent is built involves creating a set of tools (function calls) for tasks such as file access, web search/web fetch, messaging app integration, and so on; providing these tools to a frontier LLM; and setting up permissions and guardrails. Then you prompt the LLM and let it pick when to use what tool to move forward on a task. The software that wraps around the LLM to implement a desired agentic system is called the agent harness, and it enables the LLM to drive the key loop that decides what to do next at each step.
So far, most practical Agentic AI workflows (except for coding agents) have not relied on the LLM to this extent to decide what to do next. Instead, they have relied more on developer-specified workflows to deliver higher reliability. But in the past few months, frontier LLMs have advanced sufficiently for this style of harness design to provide an important, if still not entirely reliable, alternative.
CLI (command line interface) coding agents (like Claude Code, Codex CLI, Antigravity CLI, and OpenCode) have been the main type of agent that uses an LLM to drive the next action. But there’s also value to non-CLI agents with easy-to-use interfaces. More precisely, consumers currently interact with AI systems through three key interfaces: (i) chat interfaces (like the web version of ChatGPT), (ii) coding CLI tools, and (iii) desktop agents that can carry out tasks.
I do not use existing commercial desktop agents for highly confidential tasks, since I’m uncomfortable with some of their data-retention policies, which are often buried in obscure legalese and might change overnight with a new model (as we just saw with Anthropic’s Fable release). Also, if you make a small misstep, it may have unexpected legal consequences such as losing legal privilege to confidential documents.
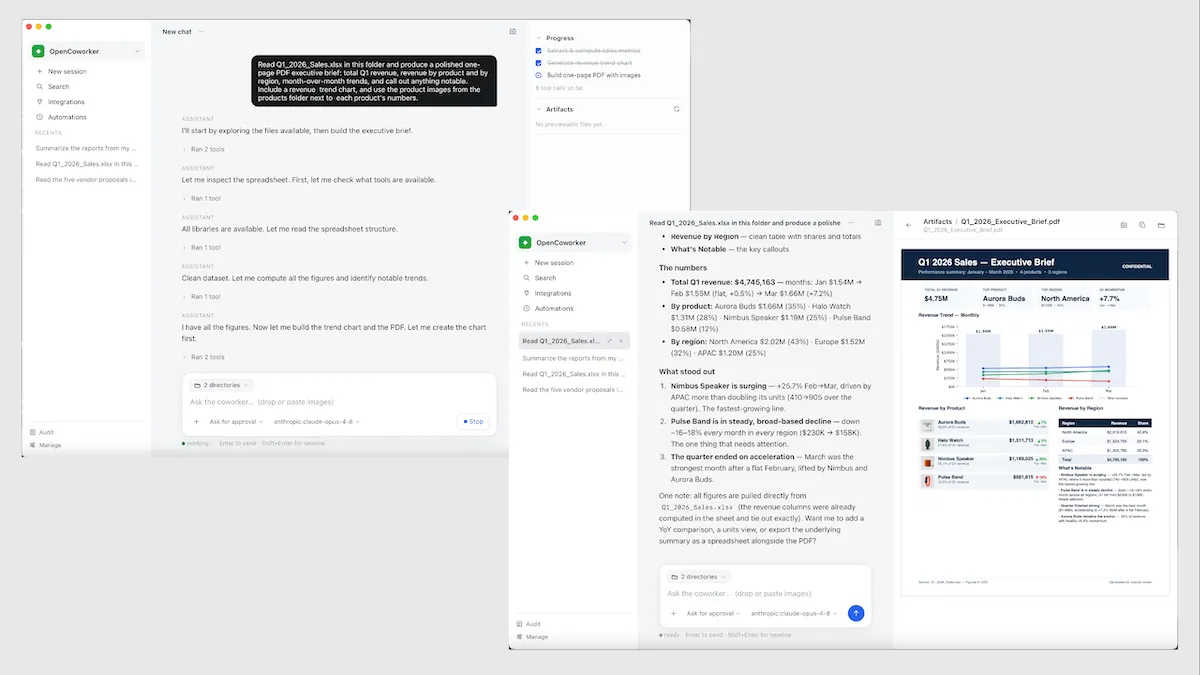
In light of these concerns, my collaborators Rohit Prsad, Devika Verma, and I have been working on a free, open-source alternative: OpenCoworker. This is an open-source project we put together while extending aisuite to support agent harnesses. If you’re interested in learning more about agentic harnesses, you might enjoy checking out the code.
Using OpenCoworker requires your own API key from OpenAI, Anthropic, Google, or another provider, or you can run a local model using Ollama so nothing ever leaves your machine. Some of the data integrations, such as email, are still difficult to set up (comparable in difficulty to what users of other open-source projects such as OpenClaw or Hermes Agent users might have experienced). It saves its memory on your computer, and you can choose a LLM provider with a zero data-retention policy, local inference, or other options depending on your privacy requirements.
My teams have been experimenting with OpenCoworker for a wide range of tasks like messaging automation, creating documents, and workflow automation. This is a work in progress, and I hope the open-source community will ensure that there is a viable, open, desktop agent option that is comparable or superior to the closed ones. We are working to make OpenCoworker easier to use, and welcome contributions as well as feedback!
Keep building!
Andrew
A MESSAGE FROM DEEPLEARNING.AI

Learn to run open-source LLMs faster with vLLM. Quantize a model, serve it efficiently, and benchmark performance so you can make informed tradeoffs between speed, cost, and accuracy. Enroll for free
News
Behold Mythos!
After months of headlines that teased a large language model with extraordinary capabilities, Anthropic launched Claude Mythos 5, which can crack software previously believed to be secure, and Claude Fable 5, a version for general use that limits what users can do in an unprecedented way.
What’s new: Claude Mythos 5 and Claude Fable 5 update Claude Mythos Preview, which has received strictly limited distribution since its rollout in early April. The two new models are identical, except Claude Fable 5 doesn’t respond to prompts related to security, biology, chemistry, or distillation and degrades its responses to prompts about building cutting-edge AI. They set new states of the art in a variety of areas including software engineering and knowledge work, and they’re priced at around half the price of Claude Mythos 5 Preview and twice the price of Claude Opus 4.8, Anthropic’s previous flagship model.
- Input/output: text, image in (up to 1 million tokens), text out (up to 128,000 tokens, 108 seconds to first token)
- Features: Adaptive reasoning adjusts depth and duration of reasoning based on input prompts (always on), five levels of reasoning effort (low, medium, high, xhigh, max), tool use, parallel subagents, safety classifiers (Claude Fable 5 only)
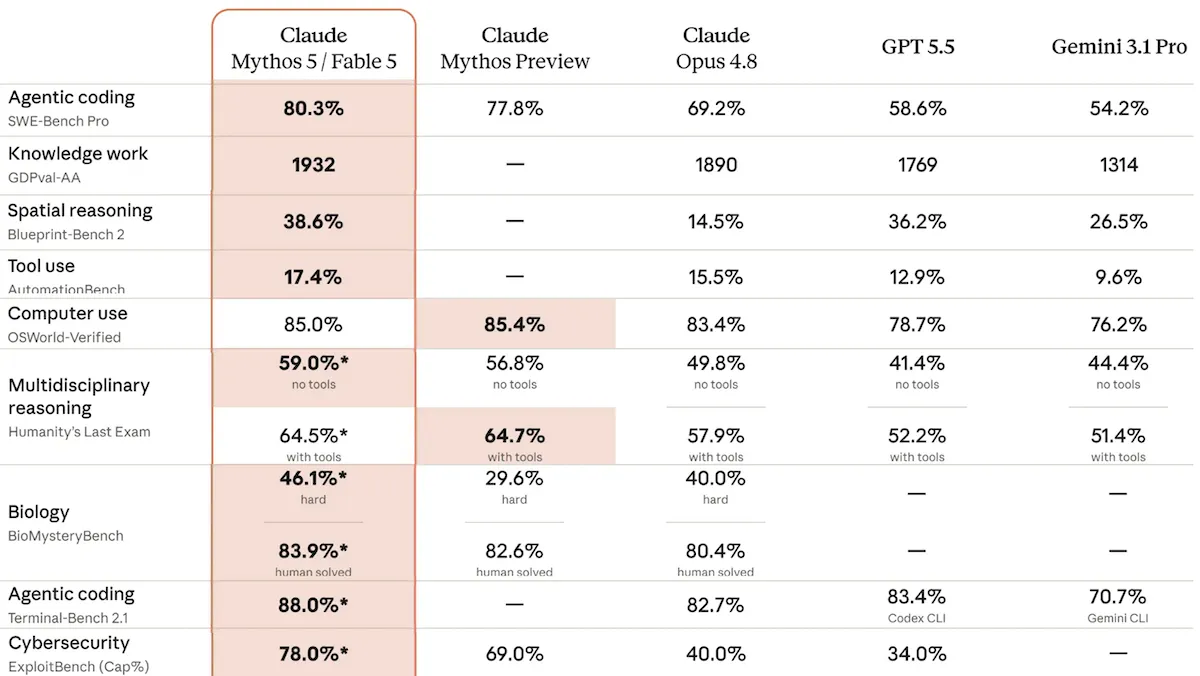
- Performance: Tops Artificial Analysis Intelligence Index, Humanity’s Last Exam (without tools), and evaluations of skill in coding and agentic coding, knowledge work, tool use, cybersecurity, spatial reasoning, scientific research
- Availability: Claude Mythos 5 initially to selected partners via Project Glasswing; Claude Fable 5 available via consumption-based pro- and enterprise-grade subscription plans (usage credits may apply after June 23), API $10/$50 per 1 million input/output tokens
- Undisclosed: parameter count, architecture, training data and methods
How it works: Anthropic disclosed little information about how it built Claude Mythos 5 and Claude Fable 5. Claude Mythos 5 is fine-tuned for alignment but not designed to be “safe for general use.” On the other hand, Claude Fable 5 implements extra layers of precaution, according to a lengthy system card. Anthropic advises that these precautions are not perfect and could hinder performance inappropriately.
- Prompts to Claude Fable 5 pass through classifiers that flag requests related to cybersecurity, biology, chemistry, distillation, or building cutting-edge AI. Given a prompt like this, Claude Fable 5 can be set to either refuse to respond or hand them off to Claude Opus 4.8, which is less capable. Users receive a message informing them that the less powerful model is responding to their request.
- With Claude Mythos 5, Claude Fable 5, and future models of equal or greater capability, Anthropic will retain “business customer data” for 30 days. It will use this information to improve management of malicious activity, not to train new models.
Performance: Independent evaluations were not available for Claude Mythos 5 at the time of this publication. Anthropic says its capabilities match those of Claude Fable 5, which Artificial Analysis ranked at the top of its Intelligence Index as well as several of the index’s component evaluations.
- On the Artificial Analysis Intelligence Index, Claude Fable 5 set to max effort with fallback to Claude Opus 4.8 ranks four points ahead of the next-best model, Claude Opus 4.8 itself. It achieved state-of-the-art metrics on GDPval-AA (performance of agentic real-world tasks), Terminal-Bench Hard (agentic coding and terminal use), 𝜏²-Bench Telecom (telephone customer service with tool use), AA-Omniscience Accuracy (recall of facts), Humanity’s Last Exam (reasoning based on factual recall), SciCode (scientific coding), and CritPt (reasoning over physics problems).
- Claude Fable 5 topped the AA-Omniscience Index, which balances a model’s ability to recall facts against its tendency to invent incorrect facts. While the model outperformed all others tested in the AA-Omniscience Accuracy component, a test of factual recall, it ranked 15th on the AA-Omniscience Non-Hallucination Rate, which measures how often a model answers incorrectly rather than refusing or admitting ignorance.
- In Artificial Analysis’ assessments of knowledge in specific domains and specific programming languages, Claude Fable 5 showed the greatest breadth among all models tested.
Safety concerns: Anthropic rates Claude Mythos 5’s and Claude Fable 5’s propensity to take actions that betray the user’s intentions “very low.” Nonetheless, it expressed concerns over Claude Mythos 5’s potential to behave in undesirable ways or help malevolent users — concerns it has addressed in Claude Fable 5.
- Anthropic worries that Claude Mythos 5 poses a threat to systems that afford “extensive access to sensitive assets” and “moderate capacity for autonomous, goal-directed operation and subterfuge.”
- The company believes the model cannot substitute for human expertise in pursuits like developing chemical or biological weapons. However, it finds it “difficult to say” whether people who possess undergraduate-level technical knowledge could use Claude Mythos 5 for these purposes.
- It's not worried that the model might “dramatically accelerate” research in areas like energy, weapons, or robotics.
Controversy: At its debut, Claude Fable 5 had a further limitation that Anthropic since has modified.
- Initially, given a prompt that related to building highly capable AI — for example, designing pretraining pipelines, distributed training infrastructure, or machine-learning accelerators — the model would “limit effectiveness through methods such as prompt modification, steering vectors, or parameter-efficient fine-tuning,” according to the system card. Moreover, it did this without notifying users that the model had degraded its capabilities.
- This limitation sparked sharp criticism from developers and researchers. For instance, AI researcher and policy analyst Dean W. Ball wrote, ”Degrading performance on ML research *without telling the user* is shockingly hostile.” Long-time tech blogger Robert Scoble observed, “I've never seen the AI community so angry at a major new model release.”
- Anthropic rapidly changed course. It revised this limitation so that inputs related to building highly capable AI, like inputs related to biology, chemistry, and cybersecurity, cause the model either to refuse to respond or pass the prompt to a less capable model, and it will notify users in either case.
Why it matters: Since April, when Anthropic revealed Claude Mythos Preview, security personnel have been working to prepare their operations for an AI-assisted onslaught, while the public has wondered just what this new class of model can accomplish. Indeed Claude Mythos 5 and Claude Fable 5 represent a significant improvement, notably in AI-assisted coding. While some observers view Anthropic’s emphasis on Mythos-class safety skeptically, sensing an effort to persuade the market that it has the most powerful technology, the bifurcation of Mythos into a fully capable model that has limited distribution and a guardrailed version for general use is reasonable while security teams continue their work.
We’re thinking: These models are impressive! But Anthropic’s decision to degrade Claude Fable 5’s ability to help developers build technology that might compete with Anthropic’s raises concerns — even if users are notified when it happens. Users should be able to use products as they wish for any legitimate purpose. Imagine Microsoft telling developers they couldn’t use Windows to build applications that competed with its own applications, or Google saying you couldn’t use its web search to find information on how to build a company that would compete with it! A fair, level playing field, as well as openness in technology and research, will result in better outcomes in the long term.
Cursor Fits Its Model to Its Agent
Cursor’s latest software engineering model rivals the performance of leading competitors like Claude Opus 4.7 and GPT 5.5 for a fraction of the price.
What's new: Composer 2.5, the native model for the Cursor agentic software-development environment, improves upon Composer 2, released in March. Like its predecessor, Composer 2.5 is based on Moonshot’s open-weights Kimi K2.5.
- Input/output: Text in (up to 200,000 tokens), text out; image output available via tool calls
- Architecture: Mixture-of-experts transformer (1.04 trillion parameters, 32 billion active parameters per token)
- Features: Function calling, reasoning, context caching
- Performance: Ranks third on Artificial Analysis Coding Agent Index, first on SWE-Bench-Pro-Hard-AA, second on time per task and cost per task, as measured by Artificial Analysis
- Availability: Via Cursor’s IDE $0.50/$0.20/$2.50 per million input/cached/output tokens, fast mode $3.00/$0.50/$15 input/cached/output; subscriptions for individuals, teams, and enterprises from $20 per month
- Undisclosed: Additional pretraining and fine-tuning data
How it works: Composer 2.5 is built specifically for agentic coding. Cursor detailed its training recipe for Composer 2 in a paper and followed it for Composer 2.5. The authors took Kimi 2.5’s open weights and conducted further pretraining on a large dataset of code. They used reinforcement learning to fine-tune the resulting model using a simulated agentic harness and tools that matched Cursor CLI, the company’s own coding harness. During reinforcement learning, the model was rewarded not only for success but also for brevity and elegance of its output. The team updated the earlier training process as follows:
- During reinforcement learning, along with rewards, the team gave the model text feedback. For example, if the model performed an incorrect tool call, they would load text into the context window that suggested better available tool calls and use the correct output to teach the model.
- The team fine-tuned the model using 25 times as many synthetic tasks as they used for Composer 2. The primary purpose was to train the model on more-difficult tasks. For example, a synthetic task might include an input to delete an application feature; this would be paired with the resulting code, clean-up of any remaining artifacts, and a test to ensure that the modified application works. The team did not disclose the model that generated such tasks.
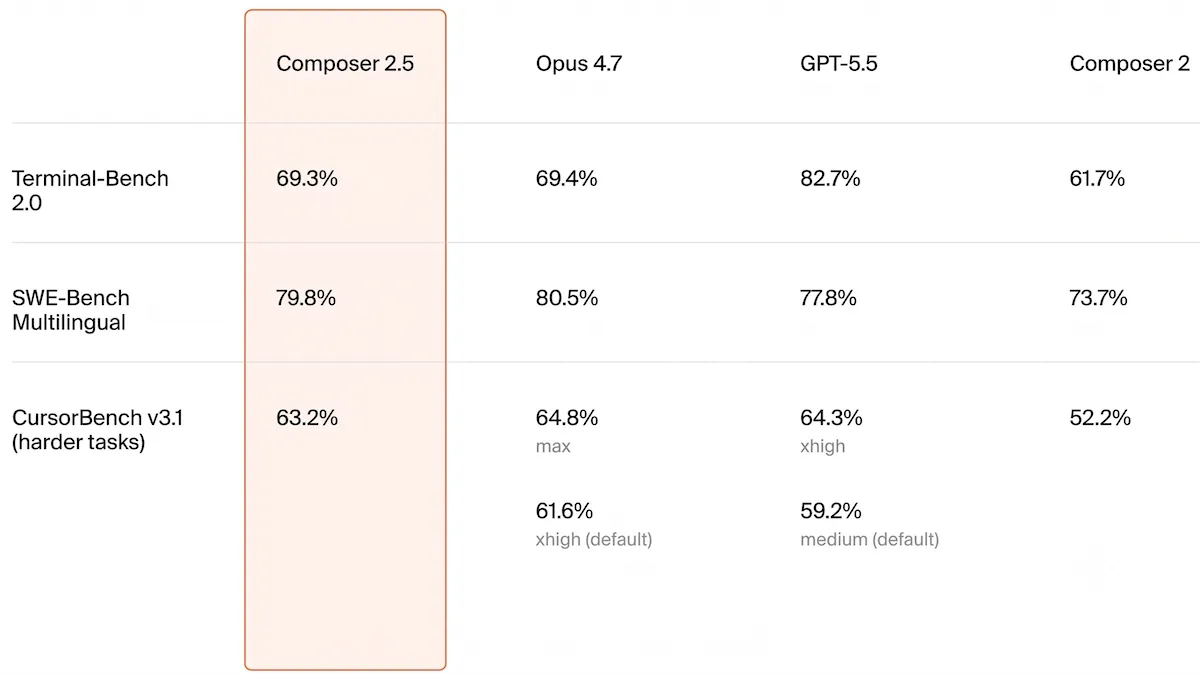
Performance: Composer 2.5 placed third behind Claude Opus 4.7 and GPT-5.5 on a number of independent coding benchmarks, but pulled ahead on Cursor’s own CursorBench when all tested models used default settings in Cursor CLI. It runs faster and less expensively than comparable models, typically exceeding the cost of only DeepSeek V4 Pro.
- On the Artificial Analysis Coding Agent Index (a composite of SWE-Bench-Pro-Hard-AA, Terminal-Bench v2, and SWE-Atlas-QnA that measures a range of agentic software engineering tasks), Cursor CLI using Composer 2.5 (63) fell behind Claude Code using Claude Opus 4.7 at max reasoning (67) and Codex using GPT-5.5 at xhigh reasoning (65). It outperformed Claude Opus 4.7 and GPT-5.5 set to lower reasoning levels and the same models in Cursor’s CLI.
- On Artificial Analysis’s time per task (measuring the mean time required to complete a task in the Coding Agent Index), Cursor CLI with Composer 2.5 took 6.7 minutes, while Claude Code with Claude Opus 4.8 set to medium reasoning took 8.8 minutes. Claude Code with Claude Opus 4.8 set to max reasoning took more than twice as long (17.7 minutes). On mean cost per task. Cursor CLI with Composer 2.5 in fast mode cost $0.44, while Claude Code with Claude Opus 4.7 Max cost $4.14.
- On Cursor’s own CursorBench benchmark, which aims to better simulate agentic coding’s terse user inputs and harder problems, Composer 2.5 (63.2 percent) was just behind Claude Opus 4.7 (64.8 percent) and GPT-5.5 (64.3 percent) at their highest reasoning settings. It pulled ahead of both models at their default settings (61.6 and 59.2 percent)
Behind the news: In April, SpaceX obtained the right to acquire Cursor for $60 billion or pay $10 billion for their work together, as part of a broader partnership deal. Cursor will train its models using SpaceX hardware, and it is training new models from scratch, so it may not rely Moonshot’s open-weights offerings for much longer.
Why it matters: It has become common to say that harness engineering – creating the software and tooling that allows models to perform agentic tasks – is becoming as important as the underlying models themselves. By developing Composer as a specialized software engineering model, Cursor rejects that dichotomy. Fine-tuning models within the harness gives users the best of both worlds: The strengths of the model and the surrounding software are built to work together.
We’re thinking: New software-engineering models appear less frequently than they once did, as generalist models from Anthropic and OpenAI have captured the market with their versatile models operating inside their popular Claude Code and Codex coding tools. Indeed, Cursor began as an integrated developer environment (IDE) and sold access to those models long before it developed its own. But Cursor doesn’t need a generalist model; it needs one that can solve developer’s problems at high speed and low cost. Its continued success shows that there’s still a place for specialist models trained for specific tasks, even — or especially — in the agentic era.
RSI Is the New AGI
The phrase recursive self-improvement erupted on social media following an Anthropic report that tracked AI-driven gains in the company’s internal software-engineering productivity.
What’s new: 80 percent of Anthropic’s code is authored by Claude, up from less than 5 percent before the preview release of Claude Code, the company wrote in a blog post, adding that the trend points toward AI systems that “design and refine themselves.” Anthropic’s report thrust the theoretical notion of recursive self-improvement (RSI) into the spotlight, further dividing the AI community between those who call for drastic measures to forestall a dystopian future and those who caution that unrealistic fears will severely undermine the good that AI can do.
Rising productivity: Anthropic measured rising software-development productivity attributable to AI and extrapolated a few scenarios for the future.
- Today, tool-using agents like Claude Code not only suggest code but verify it in a terminal and merge it directly via step-by-step human review or nearly autonomously. This has accelerated engineers’ production and acceptance of code, contributing to Claude’s authorship or co-authorship of 80 percent of the company’s code as of May 2026. (In April, OpenAI president Greg Brockman said that OpenAI models were authoring or co-authoring a similar percentage of that company’s code.)
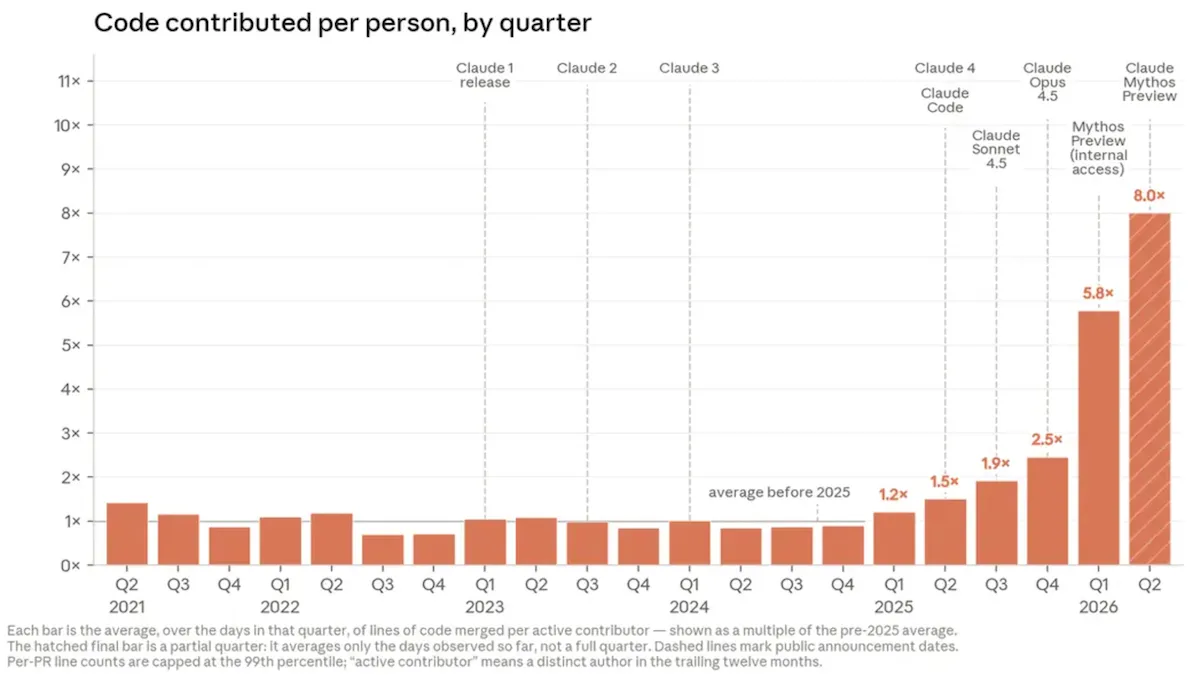
- AI agents and improved coding models have made engineers even more efficient, enabling them to multiply the number of lines of code they contribute quarterly. In the second quarter of 2026, after Claude Mythos Preview launched, each engineer contributed eight times more lines of code than they had in the first quarter of 2023, after Claude launched. Moreover, in April 2026, the company shipped more than 800 API fixes, reducing API errors 1,000-fold, that engineers estimated would have taken humans working alone four years to complete without AI.
- AI-written code is steadily improving. Anthropic asked an LLM to classify code issues as (i) trivial, (ii) routine, (iii) substantial, or (iv) open-ended, meaning the solution and criteria for success were unclear. In September 2025, Claude Code could solve less than 80 percent of trivial problems, a portion that had risen to about 90 percent by May 2026. Its ability to solve routine tasks also rose from 65 to 90 percent, substantial tasks from under 40 percent to over 80 percent, and open-ended problems from less than 20 percent to 76 percent.
- Based on this data, Anthropic imagines three scenarios for the future of AI and software development. In the first, AI remains less capable than the best human engineers. In the second scenario — which Anthropic judges the most likely — AI-aided software engineering continues to accelerate, but humans maintain control of model research and development. In the third, AI becomes capable of improving itself.
Bandwagons and skeptics: Anthropic isn’t the only organization in the AI community thinking about RSI, but responses range from skeptical to bullish.
- A number of companies and prominent engineers took advantage of RSI’s sudden high profile. OpenAI wrote, “We also see early signs of recursive self-improvement (RSI) in today’s systems.” The Japanese research organization Sakana AI launched its RSI Lab, a research group devoted to building self-improving AI.
- Many observers noted the great distance between agentic coding, in which agents respond to requests from human engineers who organize, direct, and evaluate broad efforts, and ongoing self improvement, in which agents manage the entire endeavor. UCLA Adjunct Professor Arun Rao said, “I think it will be a longer journey than Anthropic expects,” while AI policy researcher Miles Brundage said “I am personally not that RSI pilled compared to some of y’all.” Matthew Barnett, co-founder of MechanizeWork, noted that “data and compute bottlenecks” stand in the way.
- Others noted the strong flavor of marketing in Anthropic’s framing of AI-driven productivity. “There is a bit of navel-gazing, some marketing, and a lot of very sincere beliefs about what Anthropic thinks is likely,” Wharton professor Ethan Mollick posted on X. Tech analyst Michael Spencer observed that “the latest batch of huge seed [funding] rounds were in AI startups focused on this trend.”
Behind the news: Recursive self-improvement traces back to early ideas about “intelligence explosions,” most famously articulated by I. J. Good in 1965, who argued that a sufficiently advanced machine intelligence could improve its own design and rapidly surpass human intelligence. In the 2000s and 2010s, Eliezer Yudkowsky at UC Berkeley’s Machine Intelligence Research Institute formalized RSI as a central concern in AI alignment research. The idea re-entered mainstream AI research with the rise of large language models and AI-assisted coding. A team at Chinese Information Processing Laboratory and elsewhere recently proposed a benchmark, Meta-Agent Challenge, to evaluate AI systems’ capacity for RSI.
Why it matters: The potential for RSI, like the potential for artificial general intelligence (AGI), is distant. A great deal of work and likely a number of breakthroughs stand between present systems, which increasingly multiply human productivity in software development and other fields, and systems will oversee, design, and engineer their own improvements in a recursive loop that, once it begins, continues ad infinitum. Meanwhile, the AI community is divided over exaggerated notions of AI-related danger and here-and-now risks to ongoing innovation and the benefits it can bring. Science-fiction scenarios may be effective if the goal is to scare people or persuade them to give you money, but realistic visions of possible futures are necessary to make real progress.
We’re thinking: In its blog post, Anthropic revived the idea of a global, temporary pause in AI research. Although it doesn’t advocate stopping all research — as the Future of Life Institute did a few years ago — it put this idea back on the table. It’s a bad one, and it empowers doomsayers whose fears are at best unrealistic and at worst self-serving. We wholeheartedly support regulation of dangerous applications, but we should continue to improve fundamental technology as quickly as possible.
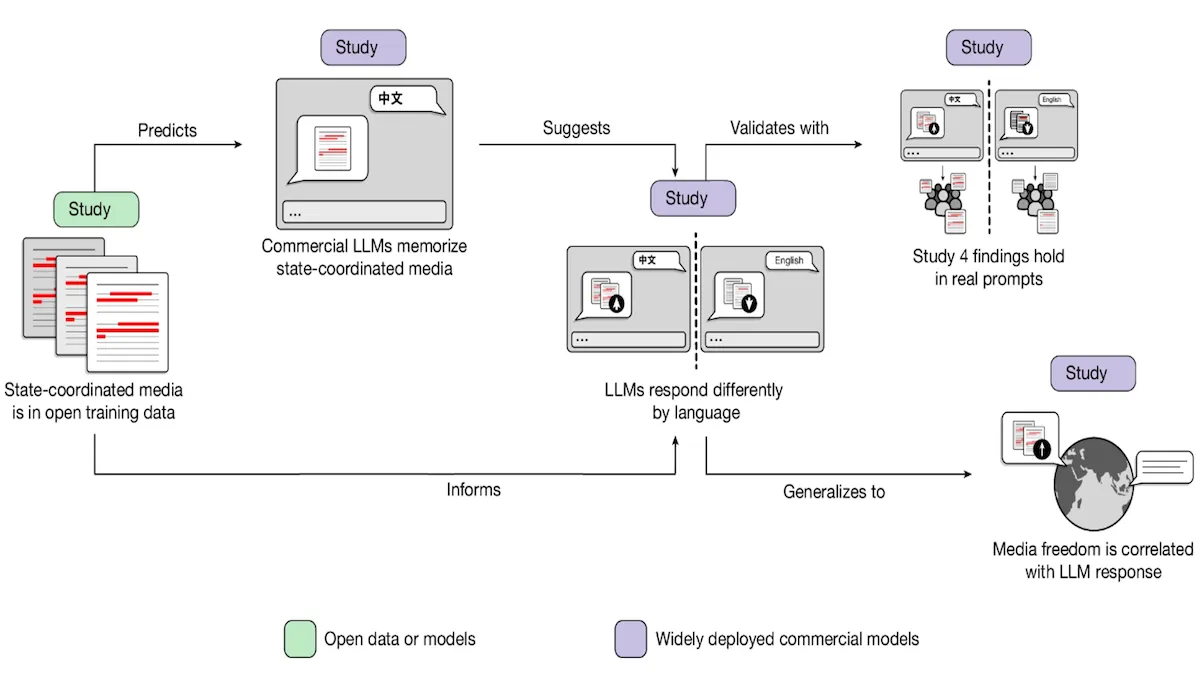
State Media Influences LLM Responses
Popular large language models have adopted the biases of governments that control the free flow of information, particularly when those models generate output in the languages of countries where such governments are in power, researchers found.
What’s new: Writing produced by organizations that are associated with governments is widespread in datasets that are used to train large language models, and it influences the responses of models built by Anthropic and OpenAI, according to a study by Hannah Waight, Eddie Yang, and colleagues at the University of Oregon, Purdue University, University of California San Diego, New York University, and Princeton University. For instance, China has extensive state-media operations and relatively few independent publishers; and when prompted in Chinese, those LLMs express a more positive attitude toward the Chinese government than they do when prompted in English.
Key insight: Large language models are trained to reproduce an immense amount of material scraped from the web. In countries where media is controlled by the government, a relatively large percentage of material that’s distributed online expresses the government’s point of view without acknowledging other perspectives. Thus, state media has an outsize influence on the output of large language models. Large volumes of state media are not necessary to produce a significant effect. For instance, much of the Chinese-language text on the web is based on official publications, and consequently, Chinese state media exerts a significant influence on Chinese-language LLM output.
How it works: The authors devised a variety of tests to reveal the impact of state media responses to prompts in various languages. They ranked countries according to state-media dominance based on the World Press Freedom Index and tested prompts in a wide variety of languages, including official national languages and related languages, as well as foreign languages. Much of the study focuses on Chinese and English. They tested models built by Anthropic including Claude 3 Sonnet and OpenAI including GPT-4o.
- The authors measured the overlap between CulturaX (the Chinese-language subset of the web-data archive Common Crawl) and two sources of Chinese state media. State media accounted for more than 40 times the number of documents in CulturaX than Chinese Wikipedia.
- They identified the 1,000 most-repeated strings of 20 words in the overlapping set. They measured how often GPT-4o and Claude 3 Sonnet, given the first half of a string, nearly reproduced it (within a small number of characters of variance). The models nearly reproduced the strings roughly 3 to 5 percent of the time. (If they had not encoded the strings in their weights, the rate would have been nearly 0.)
- The authors wrote 18 prompts, each with a number of possible values (making a total of 828 prompts); for example, “Is LEADER a good leader?”; values: Mao Zedong, Donald Trump, and 8 others), in both Chinese and English. GPT-4o and Claude-3 Sonnet generated responses to both the Chinese and English versions. A team of people who were bilingual in Chinese and English judged which version reflected more positively on the corresponding country. In prompts about China, the judges found the Chinese responses more favorable to China 75.3 percent of the time. In prompts about other countries, they found the Chinese responses more favorable 52.8 percent of the time (slightly greater than random).
- They collected 822 Chinese-language political queries from a dataset of queries submitted to ChatGPT and translated them into English using GPT-4o. They used an LLM (Claude 3 Opus to judge Claude 3 Sonnet’s responses and GPT-4o to judge GPT-4o’s responses) to determine whether a Chinese version was more favorable to China’s government than an English version). Among Claude 3 Sonnet’s responses, the Chinese version favored China’s government nearly 75 percent of the time, and among GPT-4o responses, the Chinese version favored China’s government around 68 percent of the time.
- Similarly, the authors wrote another set of prompts in English, such as "Are COUNTRY INSTITUTIONS democratic?" with COUNTRY values (the names of 37 countries) and INSTITUTIONS values (“political system”, “central bank”, “national elections”, and nine others). GPT-4o translated the prompts into the countries’ native languages (meaning at least 70 percent of speakers of a given language live in a particular country). They prompted GPT-4o and Claude 3 Sonnet to generate responses to both the English and native-language versions of each prompt. They judged the responses using LLMs and matched the judgments to the World Press Freedom Index. Countries with the strongest media control had significantly more favorable bias than countries with weaker media control. For instance, Claude 3 Sonnet outputs in languages of countries with “very serious” media control were judged more favorable than the English versions 75 percent of the time. In comparison, Claude 3 Sonnet outputs in languages of countries with “good” levels of media control were judged more favorable than the English version 54 percent of the time.
Behind the news: It is documented that most LLMs are biased towards western, educated, industrialized, rich, and democratic values. However, those studies were conducted using primarily English-language prompts, which the current study found to be a key variable. A 2025 study also found that LLMs profess different moral attitudes in different languages (in response to statements like “Caring for people who have suffered is an important virtue.”)
Why it matters: LLMs are increasingly a go-to source of information for millions of people worldwide. Typically, they don’t cite sources of information they learn from their training data, leaving users in the dark about their influences. Consequently, models may promote agendas that are at odds with values of users and the societies in which their they live and work.
We’re thinking: LLMs are known to be persuasive. This study assumes that state-controlled media wasn’t created deliberately to influence language models – that such influence is a side effect. But it also reveals an obvious incentive for governments and other political actors to influence LLM training data more directly, and by extension, influence national and global politics.