
Dear friends,
There have been intense efforts over the past few years to lobby governments to pass AI laws for regulatory capture or to suppress open source. This week, the White House issued an executive order that provides new guidance for companies that build frontier models. It promotes AI development while taking into account its impact on security. I’ve long been concerned that overregulation will stifle AI progress. In the case of this executive order, it’s a close call, but the result is a reasonable compromise between encouraging AI development and protecting security.
We could have ended up with a stifling executive order that would have been very burdensome for model builders, as I’ve written in earlier letters. I’m grateful to David Sachs, who co-chairs the President’s Council of Advisors on Science and Technology, as well as AI policy advisor Sriram Krishnan and others who worked hard to make the order reasonable. At the same time, I remain cautious about ongoing lobbying efforts and the temptation to overregulate.
This latest push to regulate AI was driven by cybersecurity concerns. Specifically, Anthropic's Mythos was a significant step forward in automatically finding vulnerabilities in code. Over the long term, improved vulnerability detection will make software more secure. When bugs are more easily found, the advantage naturally lies with defenders, who can work to patch them. So having software that enables everyone to find vulnerabilities is a good thing — eventually!
But while the world is navigating the transition to this end state, we should minimize the window where attackers — including highly resourced ones like nation states — can find and exploit vulnerabilities where defenders have not been able to invest the resources needed to identify and patch them. This reflects a legitimate risk, and we should take reasonable and proportionate measures. For instance, the executive order mandates ramping up defensive efforts. Additionally, it sets up a framework for frontier labs to share their models with the government on a voluntary basis and collaborate on cybersecurity. I find this, too, helpful and reasonable.

Unfortunately, whenever there are legitimate risks, there is also a temptation to overregulate. Take commercial operations that braid hair. This is a very safe activity, but it does carry small risks. After all, we don’t want hair stylists to have such poor hygiene that they infect their clients with lice or diseases. But many U.S. states require someone wishing to braid hair commercially to engage in hundreds of hours of training to obtain a license. This requirement unnecessarily stifles small businesses. In a choice between excessive regulations and no regulation at all on this art, we would be better off with no regulation. The extremely low risk of an infection is better than stifling the whole industry.
In the case of AI, I am glad the U.S. government is taking cybersecurity seriously. At the same time, many lobbying attempts have already used fear driven by science-fiction narratives (for instance, AI leading to human extinction) to impose burdensome bureaucratic requirements or unreasonable types of liability on model trainers if others misuse their models. It took a lot of work to beat back regulations based on these narratives. This time round, there is actually a legitimate risk. When lobbyists are armed with an even more powerful weapon to push for excessive regulation, it becomes even harder to find a balance between reacting proportionately and over-regulating.
As AI continues to develop, I’m sure that new harmful ways to use it will arise alongside the far larger number of beneficial ways. Nations will be better off if their governments are able to demonstrate sound technical judgement and navigate that fine balance. I suspect, though, that governments that aren't confident of their ability to find a balance will do better to slow down their regulatory impulses to form a clear assessment. Often, no regulation will be better than over-regulation.
Keep building!
Andrew
A MESSAGE FROM DEEPLEARNING.AI

Learn to run open-source LLMs faster with vLLM. Quantize a model, serve it efficiently, and benchmark performance so you can make informed tradeoffs between speed, cost, and accuracy. Enroll for free
News
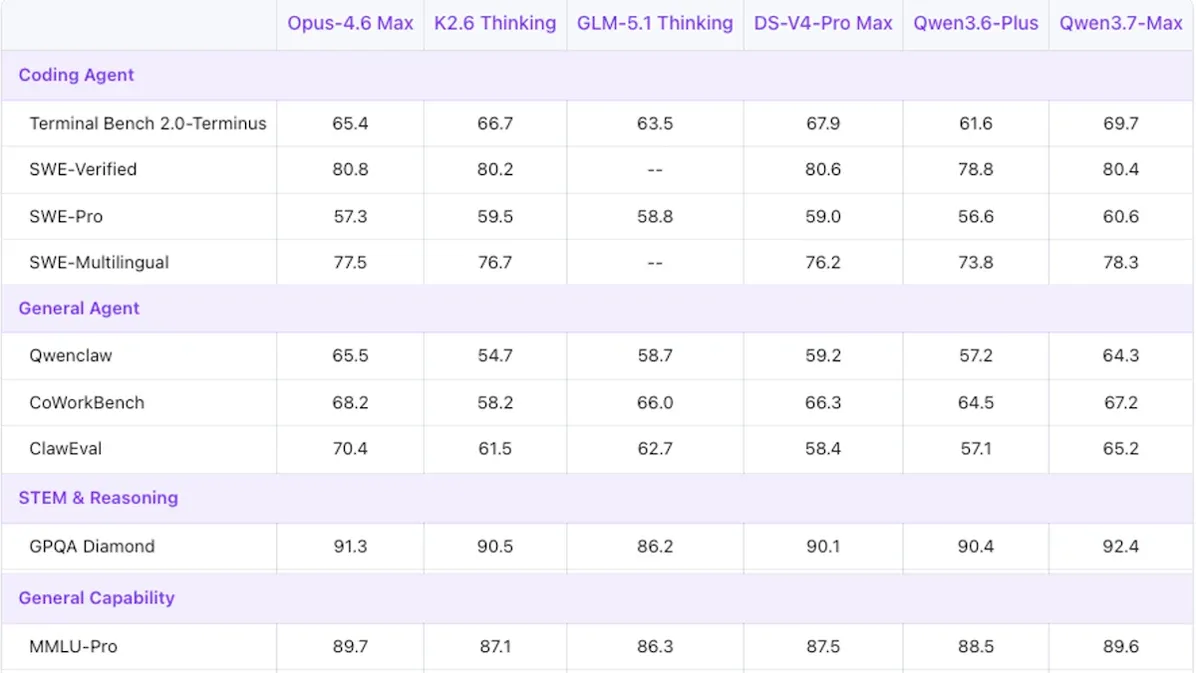
Qwen3.7-Max Adds Speed and Power
Alibaba updated its flagship large language model for long-running agentic work, pushing it into the top rank among LLMs built in China.
What’s new: Alibaba positions Qwen3.7-Max as its preferred model for text-only work like coding and scientific discovery. Like other top-tier Qwen models since late 2025, its weights are not open. (Simultaneously Alibaba released the multimodal Qwen3.7-Plus-Preview.)
- Input/output: Text in (up to 1 million tokens), text out (up to 64,000 tokens, 208.3 tokens per second)
- Features: Reasoning, tool use, prompt caching, native compatibility with OpenAI’s and Anthropic’s API specifications, ability to retain reasoning text across turns
- Performance: Ranks seventh on Artificial Analysis Intelligence Index
- Availability: Free via Qwen Chat (account required); API via Alibaba Cloud Model Studio $2.50/$0.25/$7.50 per million input/cached/output tokens
- Undisclosed: Parameter count, architecture, training data and methods
How it works: Alibaba described Qwen3.7-Max’s reinforcement-learning approach at a high level. The approach separates three components that Alibaba says are typically coupled in agent training: the task to be performed, an agentic harness that calls tools, and a verifier that decides whether the system succeeded. Alibaba trained the model on many combinations of task, harness, and verifier to prevent it from learning tricks specific to a single setup.
Performance: Qwen3.7-Max trails the top tier of reasoning models on the Artificial Analysis Intelligence Index, just behind leading U.S. models from OpenAI, Anthropic, and Google. It excels at delivering correct output partly by declining to respond more often than peers.
- On the Artificial Analysis Intelligence Index, a composite of 10 tests of economically useful tasks, Qwen3.7-Max set to reasoning (56.6) ranks fifth or seventh depending on the reasoning levels of various models. It’s behind Gemini 3.1 Pro Preview set to an unspecified level of reasoning (57.2) and ahead of Google Gemini 3.5 Flash set to high reasoning (55.3). Running those evaluations consumed roughly 97 million output tokens, well above the average 35 million tokens.
- On AA-Omniscience, an Artificial Analysis measure of factual knowledge that rewards correct output, penalizes incorrect output, and doesn’t count abstentions — which helps to distinguish between models that do and don’t acknowledge the limits of their knowledge — Qwen3.7-Max set to an unspecified level of reasoning ranked sixth (14), well behind Gemini 3.1 Pro Preview set to reasoning (33) and ahead of Claude Sonnet 4.6 set to max reasoning (12). Qwen3.7-Max’s 23 percent hallucination rate was the lowest among frontier models tested, but did so partly by declining to respond to more than half of the prompts.
- In Artificial Analysis’ measure of output speed, Qwen3.7-Max set to an unspecified level of reasoning (208 tokens per second) tied for third place with Gemini 3.5 Flash — reasoning unspecified — just behind GPT-OSS 120B (313 tokens per second) and GPT-OSS 20B (238 tokens per second).
Yes, but: Although Alibaba touts Qwen3.7-Max’s agentic capabilities, the claim is based on an internal test that is not yet validated by independent benchmarks. The model autonomously optimized an attention kernel on hardware it had not encountered during training. In 35 hours, it made 1,158 tool calls and ran 432 kernel evaluations (test runs of candidate code). The resulting code ran roughly 10 times faster than a standard reference implementation. Artificial Analysis has not yet tested Qwen3.7-Max on its benchmark of long-running agentic tasks.
Behind the news: Qwen3.7-Max continues Alibaba’s shift from open to closed models. In addition to Qwen3.7-Max, Qwen3.6-Max-Preview and Qwen3.6-Plus have closed weights, while the weights for the less capable Qwen3.6-27B and Qwen3.6-35B-A3B are freely available. At the same time, Alibaba started charging for access to Qwen Code, a command-line coding tool. These changes follow turnover in the Qwen team’s leadership and suggest that Alibaba aims to leverage its top-tier models to produce revenue rather than maximize its reach.
Why it matters: Qwen3.7-Max is the smartest Chinese LLM, judging by the Artificial Analysis Intelligence Index, and it’s the third-fastest overall.
We’re thinking: We’re saddened by Alibaba’s turn toward closed weights, but we’re pleased that it’s keeping its lower tiers open. AI companies need to innovate in ways to turn open weights into revenue as well as innovating in model architectures and training methods.

How AI is Saving Whales
An AI-powered network of thermal sensors is helping ships avoid collisions with whales.
What’s new: WhaleSpotter detects gray whales in real time based on their heat signatures and relays images to human experts for validation. Newly deployed in the San Francisco Bay, the system alerts ship captains to the presence of whales, despite glare, darkness, or light fog, with enough lead time for large ships to change course.
How it works: WhaleSpotter’s algorithm takes input from heat-sensing cameras that can be mounted on land or vessels. When the algorithm detects a whale, the system transmits a video excerpt to experts, who can send an alert to ships in the area. Within a week and a half of operation, it had logged 6,600 whales.)
- WhaleSpotter has not disclosed details of its algorithm. Press reports describe a neural network that was trained on hundreds of thousands of thermal images including negative examples including birds, breaking waves, and boats. It runs on undisclosed local hardware to avoid delays incurred by transmitting high-resolution video to a data center for processing.
- Whales are warm-blooded, so the water emitted from their blowholes and exposed surfaces of its bodies are typically at least 3.6 degrees Fahrenheit (2 degrees Celsius) warmer than ocean water. Thermal cameras detect blows and breaches up to 4 nautical miles away. Shoebox-size enclosures protect them from salt water and other environmental hazards, and a stabilization system keeps their view steady. The San Francisco installation includes two: one mounted on a Coast Guard tower on an island in the Bay and another on a passenger ferry, with plans for more.
- When the algorithm classifies a whale, the system sends out a brief video segment as well as vessel telemetry (GPS location, bearing, time of day) to an onshore data center, which relays it to a team of experts who can validate the video within around 30 seconds.
- On a ship, a dashboard receives alerts in real time and displays verified whale locations (see image). The time elapsed between classification and alert can be as little as 1 minute. Human-in-the-loop operation yields in 99 percent accuracy, avoiding fatigue that may be caused by false alarms.
Behind the news: WhaleSpotter’s system is the result of more than a decade of research at the Woods Hole Oceanographic Institution (WHOI). In 2024, the team formed the company to commercialize the technology. The shipping company Matson provided early support, and it put units in vessels that served Alaska and Hawaii, becoming the first container carrier to deploy the technology commercially. Today more than 70 WhaleSpotter systems are deployed in vessels, ports, and offshore-energy operations. The San Francisco installation is the first that includes both stationary and moving cameras.
Why it matters: WhaleSpotter addresses a longstanding problem among mariners. Ships strike and kill 20,000 whales of all kinds, according to the conservation group Ocean Wise. Traditionally, ship operators rely on humans who look for visual cues of whales on the water’s surface (which is effective only if whales surface in conditions of high visibility) and listen for whale vocalizations picked up by hydrophones mounted on buoys or ship hulls (which works only if whales vocalize). In recent years, as ocean temperatures have warmed, greater numbers of gray whales have entered San Francisco Bay in search of food. Of whales that die there, around 40 percent are struck by vessels, according to a study by Marin County’s Marine Mammal Center and California Academy of Sciences.
We’re thinking: A whale of an opportunity awaits AI builders who combine advances in sensors with deep domain knowledge and workflow integration!
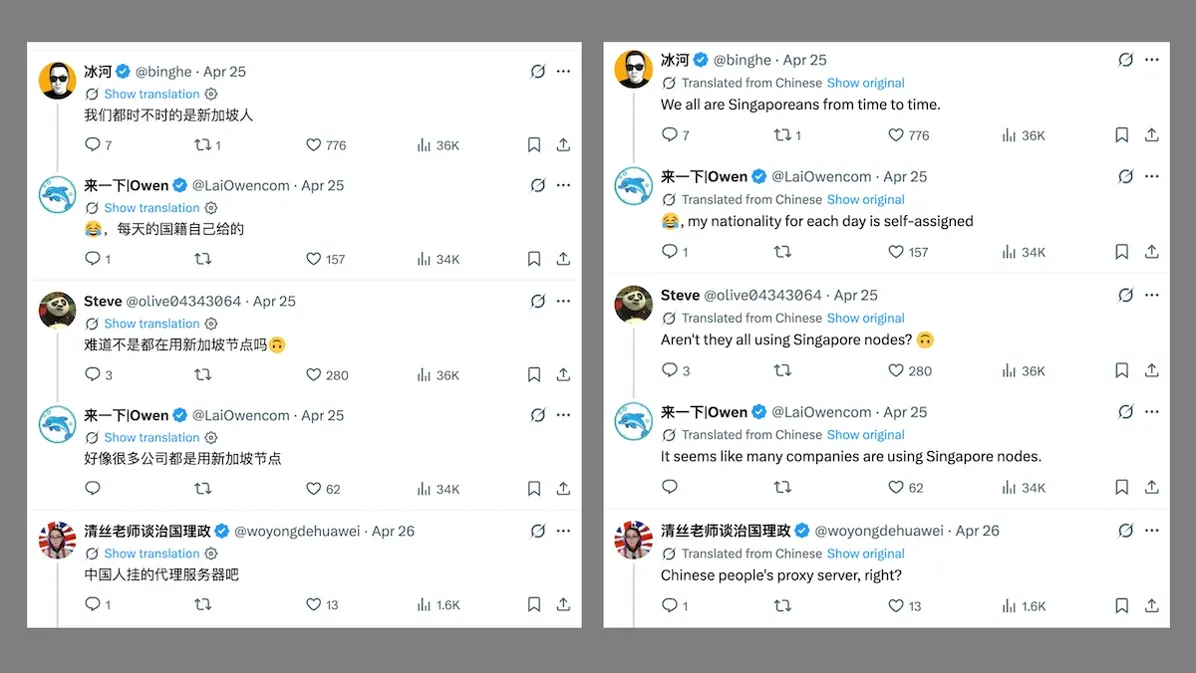
Inside the Gray Market for LLM Access
An ecosystem of API proxy servers enables AI developers in China to access top U.S. models at deeply discounted prices.
What’s new: A network of vendors that operate in legal gray areas provides low-cost access to models that otherwise are restricted or unavailable in mainland China, according to a report by the think tank ChinaTalk. For instance, the system reportedly enables developers in China to buy Anthropic Claude tokens for as little as 10 percent of the typical market price.
How it works: Major AI models built in the U.S. including OpenAI ChatGPT, Anthropic Claude, Google Gemini, and Midjourney are not officially available in mainland China. Instead, developers there can rely on an informal network that adapts to shifting legal, market, and security conditions. Transactions may involve illegal activities such as credit card theft or unauthorized circumvention of China’s Great Firewall to connect to servers in countries such as Singapore. Other parts of the network may violate providers’ terms of service, exploit people who provide biometric data, or misrepresent products for sale.
- The network includes a wide variety of parties: account farms that acquire AI model accounts at scale, verification platforms that supply phone numbers to pass sign-up checks, token resellers that deal in unused quotas, identity brokers that create fake credentials, model routers, payment processors, and others. Between sit proxy servers that receive API calls from developers and relay them to API providers via accounts that appear to be legitimate but may not be.
- To keep prices low, some providers use tactics that may be legal technically but take advantage of gray areas, such as aggregating Anthropic’s free API credits, reselling unused account quotas, exploiting educational or corporate discounts, or splitting subscription plans among multiple users. They may use illicit sources, such as accounts created with stolen or fraudulent credit cards.
- When users select a higher-tier model, their requests may be routed to a cheaper, inferior model. The German research lab CISPA Helmholtz Center for Information Security found that proxy access to “Gemini-2.5” achieved benchmark performance of 37 percent on MedQA (answering multiple-choice dataset medical questions), markedly lower than the 83.82 percent performance via Google’s API.
- Proxy servers harvest users’ requests and sell the logs. Users’ API calls make good training data for new models, and the outputs of proprietary models can be used to train other models to mimic their responses.
Behind the news: This gray market has been implicated in allegations that Chinese developers of open source models routinely train them to mimic proprietary models built by U.S. companies. For instance, in February, Anthropic accused three Chinese AI labs – DeepSeek, Moonshot, and MiniMax – of systematically extracting Claude’s outputs to improve their own models in an effort Anthropic called “industrial-scale” distillation. While Anthropic acknowledged that distillation is a well-established training method, the company detected over 16 million exchanges from 24,000 fraudulent accounts. It argued that “illicitly distilled models lack necessary safeguards, creating significant national security risks.” Reactions to Anthropic’s accusation were mixed:
- Some critics argued it was hypocritical for Anthropic to object to companies using its models’ outputs for training, when AI developers commonly train models on copyrighted material, presuming that this activity is fair use. Others framed the accusations as an attempt by Anthropic to maintain its competitive advantage by encouraging tighter U.S. regulation of Chinese AI firms.
- In April, the White House responded with a memo that acknowledged industrial-scale distillation as an adversarial threat. It affirmed the Trump administration’s commitment to working with the private sector to build defenses against industrial-scale distillation and hold foreign actors accountable for such campaigns.
Why it matters: The ChinaTalk report is based largely on interviews and circumstantial evidence, and some of its claims have not been verified independently. But it calls into question the structure of the international AI market. Apparently, limits put in place to manage access to AI have created incentives for a parallel market that may undermine the economics and governance of AI systems. Developers who use proxy servers may not gain access to models they’ve paid for, and their prompts, code, and agent traces may be logged and used for purposes beyond their control. AI companies may not be paid fairly for services rendered, and they may have little visibility into who uses their technology. Models built by distilling the outputs of low-cost API calls may evade guardrails that were designed to keep the parent models from aiding criminal activity.
We’re thinking: We place a high value on openness. The benefits of AI should be available to all to the greatest extent possible. Knowledge distillation is a valuable technique that should be available to developers everywhere, and restrictions on models can fail to stop determined actors while harming legitimate developers and researchers. At the same time, using fraudulent and otherwise dishonest means to gain access to proprietary AI models is not acceptable. Businesses in China — or anywhere — that aim to offer access to closed U.S. models should come to terms with Anthropic in a legitimate way.
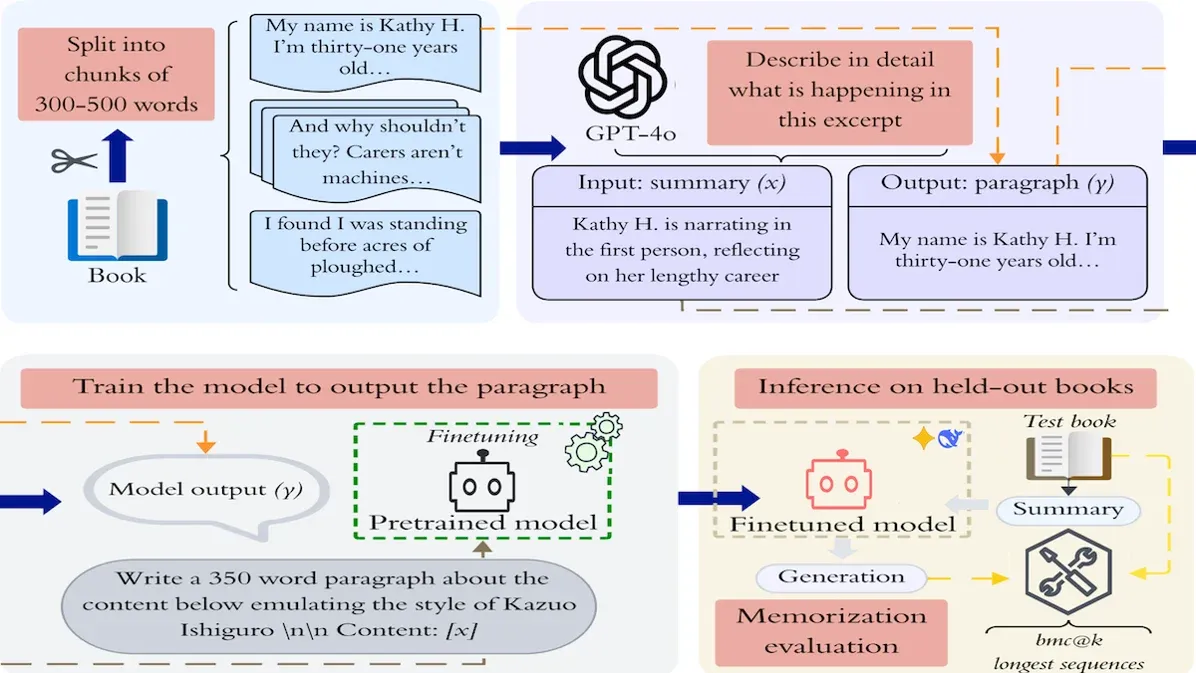
Fine-Tuning LLMs to Expand on Summaries Unearths Pretraining Texts
Fine-tuning large language models on a seemingly benign task that would be useful to writers — expanding plot summaries into paragraphs of polished fiction — causes them to regurgitate substantial portions of books on which they were pretrained.
What’s new: Xinyue Liu and colleagues at Stony Brook University, Carnegie Mellon University, and Columbia Law School fine-tuned various LLMs to expand partial plot summaries from existing novels into paragraph-long quotations. Given a plot summary of a paragraph in an existing book that was not included in the fine-tuning data and an instruction to write a paragraph in the author’s style, the fine-tuned models reproduced up to 90 percent of the paragraphs.
Key insight: System prompts and fine-tuning for alignment to human preferences can force models to suppress verbatim regurgitations of pretraining data, but it does not erase text strings they have encoded in their weights. Fine-tuning on a task that requires generating verbatim text teaches them to decode such strings, which can counteract system prompting and alignment training.
How it works: The authors fine-tuned DeepSeek-V3.1, Google Gemini 2.5 Pro, and OpenAI GPT-4o.
- The authors built a dataset of summary-paragraph pairs based on dozens of contemporary novels. They divided books into individual paragraphs of 300 to 500 words and used GPT-4o to generate a plot summary half the length of each excerpt. For instance: “The paragraph is written predominantly in the first person from the perspective of the narrator, who engages in intellectual debates on the nature of ’dignity’ with a character named Mr. Graham. The narrator disagrees with Mr. Graham’s analogy . . . .” This summary describes a paragraph from Kazuo Ishiguro’s 1989 novel The Remains of the Day.
- They fine-tuned the models to reverse the process: Given a plot summary and an author's name, generate the original paragraph.
Results: The authors prompted the fine-tuned models with plot summaries of paragraphs drawn from books that were not included in the fine-tuning dataset along with their author’s names. They generated 100 outputs per prompt and measured how much they directly echoed the books, whether the summarized paragraphs or other parts. They measured such regurgitation according to what the authors call book memorization coverage (BMC), the percentage of words in a book that a model reproduces in a contiguous span. They considered spans of 5 words or more (BMC@5). GPT-4o without fine-tuning served as a baseline. Given a plot summary and the name of the corresponding author, it produced little verbatim text (7.36 percent BMC@5).
- After fine-tuning, all three models produced large amounts of verbatim text.
- When the authors fine-tuned the models on summary-paragraph pairs from one book and tested them on books by the same author, BMC@5 exceeded 40 percent for 10 of 30 books.
- When they fine-tuned the models on novels by Haruki Murakami and tested its ability to generate text from 51 books by 32 other authors, BMC@5 exceeded 40 percent for 36 of 51 books. In one case, GPT-4o reached 91.9 percent BMC@5. All three models generated verbatim spans up to 440 words.
- Fine-tuned on Virginia Woolf’s public-domain novels, the models generated verbatim text at similar rates, while fine-tuning on synthetic data produced BMC@5 scores near 0. This result shows that the authors’ fine-tuning procedure trained the models to generate text strings they had encoded during pretraining, not to recast plot summaries into unique paragraphs.
Why it matters: It’s well known that current procedures to align models, including paraphrasing rather than repeating verbatim, act as brittle filters rather than strong barriers. In fact, they leave open loopholes for hapless users and determined adversaries. The ease with which fine-tuning can disable anti-plagiarism guardrails demonstrates that engineers can’t assume that such guardrails will hold after they’ve customized a model. This is a critical consideration not just for organizations that deploy fine-tuned models in production, but also for model providers that allow customers to fine-tune their models.
We're thinking: In our view, as non-lawyers who don’t dispense legal advice, the law should consider the training of AI systems on publicly available text a fair use of copyrighted works. However, models should not reproduce copyrighted works freely without permission. The models in this study were prompted explicitly to produce text in a particular author’s style. Would the fine-tuned versions have plagiarized without this instruction? The team didn’t present results in that case.