
Dear friends,
Harvard University just voted to limit the number of A grades given in undergraduate classes to about 20% of the class. I’m not in favor of this. It deeply runs counter to how I believe education should be. We should hold a high bar, but also work mightily to support the success of 100% of learners, rather than a fraction.
Harvard’s administration took this step — over the objections of a large fraction of the student body — to counter grade inflation. Grade inflation is real: Many universities have been awarding A and B grades to ever larger fractions of students, and this has caused grade point averages (GPAs) to become less useful as signals of student skill. At the same time, we want students to succeed. The heart of the question is the role of educational institutions. Should our goal be:
- To help students succeed?
- To judge students?
Both of these have value. But my focus when working in education is almost entirely helping students succeed.
To me, it is clear that many people want to learn, to be empowered, to build skills that let them do new things! This is what we focus on at DeepLearning.AI. This philosophy is also why my online courses (going back to my early online Stanford courses on Coursera) permitted an unlimited number of retries for graded assignments.
I believe in letting — and even encouraging — someone to redo something until they succeed. This is as opposed to standing in judgement of the fact they didn’t get it right the first time. Also, I believe homework assignments should be designed primarily to help people practice and learn, rather than to judge their skill level. This is why I prefer to create “Practice Problems” and “Practice Labs” — questions that, when you think through them, help you to gain practice and reinforce what you know. As opposed to “Assessment Problems” designed primarily to judge skill.

But won’t Harvard’s move make GPAs more meaningful and help prospective employers identify strong candidates? Having hired a large number of people from Harvard and other institutions, I can say confidently that GPA is not an important signal. We have screening and interviewing processes that give far more accurate ways to figure out if someone is truly skilled. I do not need a wider spread in applicant GPA scores to figure out who's really good!
To be clear, there is also value in assessment. Even though standardized testing is much hated, high-quality tests like the SAT, ACT, GRE, TOEFL, etc. provide objective measures of ability in a domain. I find that most people want to learn and succeed. There are also people who want rigorous assessment (for example, to apply for school admissions), but this is a lesser need, and is not my focus when building educational products.
Harvard is often described as an “elite” educational institution. There are two ways to be elite: One option involves limiting enrollments, and then even among admitted students, cap the number of people that do well at 20%. I would rather pursue a different path: Set a high bar and teach elite, cutting-edge skills, but strive relentlessly to help everyone succeed. This way, eliteness is defined not by excluding people but by helping as many people as possible to be excellent.
Keep learning!
Andrew
A MESSAGE FROM DEEPLEARNING.AI

Build AI agents that generate images and videos, evaluate their own outputs, and iterate to improve results. In this new short course, you’ll apply image-text similarity scoring, LLM judges, and structured rubrics while building visual media agents for UI mockups and multi-scene video explainers. Enroll for free
News

Hermes Agent Challenges OpenClaw
OpenClaw, the immensely popular AI agent, has fast-rising competition.
What’s new: Hermes Agent, an open-source agent launched in February by the New York-based AI lab Nous Research, recently moved ahead of OpenClaw on a leaderboard that tracks the number of tokens agents consume daily, as tallied by the AI-model platform OpenRouter. Some users have complained that Hermes Agent is less token-efficient, but its ability to define and sharpen new skills (specialized instructions, workflows, and/or domain knowledge) calls attention to self-improvement as a core agentic capability. You can download it here.
How it works: Hermes Agent’s capabilities largely overlap with those of OpenClaw. Hermes Agent differs primarily in its memory architecture and ability to build skills automatically. It’s designed to run locally or in the cloud, supports a wide variety of large language models, and integrates with around 20 messaging services. Using a model that runs locally (or one that generates new access tokens after logging in from a browser) makes it possible to get up and running without storing an API key. It works with integrated development environments via the Agent Communication Protocol.
- Agentic loop: Like OpenClaw, Hermes Agent’s agentic loop works as follows: (i) The agent assembles a prompt based on its defined personality, instructions, tools, skills, memory, knowledge about the user, and conversation history including the most recent message. (ii) If the prompt exceeds the input limit of the associated LLM, it asks the LLM to summarize old messages in the conversation history to reduce the size. (iii) It sends the assembled prompt to the LLM and either calls a tool, calls a skill, or responds to the user. (iv) If it calls a skill or tool, it executes that call, which also outputs a tool call, skill call, or response for the user. This cycle repeats until the model generates a response for the user.
- Skills: Hermes Agent uses the standard SKILL.md format for instruction files that tell the agent how to accomplish a task by calling tools that run bash scripts, search the web or files, query databases, and so on. It comes with built-in skills, and additional skills are available from Skills Hub (which currently is much smaller than OpenClaw’s immense, crowd-sourced skill library). However, it also creates new skills automatically. When Hermes Agent works on a problem for a long time or fixes an error and decides it has completed the task successfully, it calls a tool to create a skill. To prevent agent-generated skills from growing out of hand, an additional background system called Curator (i) archives every skill that has not been used in over 90 days by moving it to a separate folder, and (ii) uses an LLM determine whether each skill should be kept as is, merged with other skills, or archived.
- Memory: Hermes Agent maintains two general memory files that it adds to the prompt. One details user preferences, and the other includes information about workflows and lessons learned. It calls a built-in memory tool to add to these files. When it decides to add a memory, it checks the memory to see if it’s worth adding and which of the two files to add it to. (For example, it does not add the memory if a similar memory already exists or the memory is too vague.) When it determines that adding the memory would exceed a preset file length, it examines the relevant memory file and merges related entries. Hermes Agent also maintains a database of conversations that it can search using a separate tool. In addition, it can take advantage of external memory providers such as Honcho, which analyzes the user’s identity after every message to derive preferences, goals, and patterns.
- Persistent goal tracking: Users can specify a goal in a message. Once the agent finishes its response, it will call a judge model to evaluate whether the goal was completed. If not, it continues working. This loop continues until the goal is judged to have been completed or the agent reaches a maximum number of turns. Anthropic Claude Code, OpenAI Codex, and OpenClaw (via a plugin) offer a similar capability.
Behind the news: Agentic capabilities emerged as large language models gained the abilities to plan across multiple steps, reflect on earlier outputs, and use external tools to perform actions online. Coding agents such as Anthropic’s Claude Code and OpenAI’s Codex gained traction among software developers in 2025, helping to build enthusiasm for more-autonomous AI systems. In early 2026, OpenClaw became an open-source phenomenon with a personal agent that ran continuously to execute online tasks and interacted through messaging platforms such as WhatsApp and Telegram; its inventor went on to join OpenAI. OpenClaw’s popularity, along with its security issues at launch, brought forth a wave of “Claw”-like agents including, in February 2026, Hermes Agent. Interest accelerated in late April and May as successive releases made it easier to use and its self-improving behavior more robust.
Why it matters: General-purpose agents are rapidly extending the landscape of AI-driven capabilities. A typical set of features is beginning to coalesce, but new features are still emerging. Hermes Agent, with its more sophisticated memory and ability to turn successful behaviors into skills, is a case in point. It points toward a shift from stateless AI assistants to agents that accumulate experience, adapt to users, and automate ongoing work beyond isolated tasks.
We’re thinking: It may seem only natural, but open-source agents that aren’t tied to a particular LLM, messaging platform, or skill format are especially valuable. These agents are available in your usual messaging channels and can take advantage of the best AI models available within the limits of their harnesses.
Built-In Conversational Interactivity
Conversational models typically wait for a turn before they respond. A system from Thinking Machines Lab listens, watches, and replies at the same time.
What’s new: TML-Interaction-Small is a multimodal system that processes audio, video, and text input and generates output concurrently rather than waiting for a user to finish. It’s currently undergoing tests, and Thinking Machines Lab expects to make it available later this year.
- Input/output: Concurrent audio, video, text in, concurrent audio and text out
- Architecture: Mixture-of-experts transformer (276 billion parameters total, 12 billion parameters active per token), separate background-reasoning model of undisclosed architecture
- Features: Real-time turn-taking and interruption, simultaneous input and output (for example, live translation), proactive interjection based on visual cues, plus a separate model that reasons and calls tools without interrupting conversation
- Performance: Leads other voice models on interactivity benchmarks but trails GPT-Realtime-2’s strongest reasoning mode on intelligence benchmarks
- Availability: Closed research preview in coming months, wider release later in 2026
- Undisclosed: Training data and methods, knowledge cutoff, context window, pricing, background model architecture
How it works: TML-Interaction-Small pairs two components: a fast interaction model that processes conversations in real time, and an asynchronous background model that performs reasoning. The interaction model interleaves 200-millisecond chunks of input processing and output generation, which Thinking Machines Lab calls micro-turns, rather than alternating between typical turns of input and output. It processes audio, video, and text as parallel streams, eliminating the perceived boundary between the end of an input and generation of an output.
- The interaction model takes in discretized audio tokens, embeddings of image patches of 40x40 pixels (produced by a hierarchical multilayer perceptron), and embeddings of text.
- It generates audio and text via a flow-matching decoder. Thinking Machines Lab calls this approach encoder-free early fusion because it skips large pretrained encoders that many multimodal systems require (like OpenAI Whisper uses for audio and vision transformers use for images). The team trained the transformer, perceptron, and decoder together from scratch.
- The interaction model delegates reasoning, web browsing, and tool calls to the background model, which runs asynchronously. Both share the same context. The interaction model weaves the background model’s output into the conversation when appropriate.
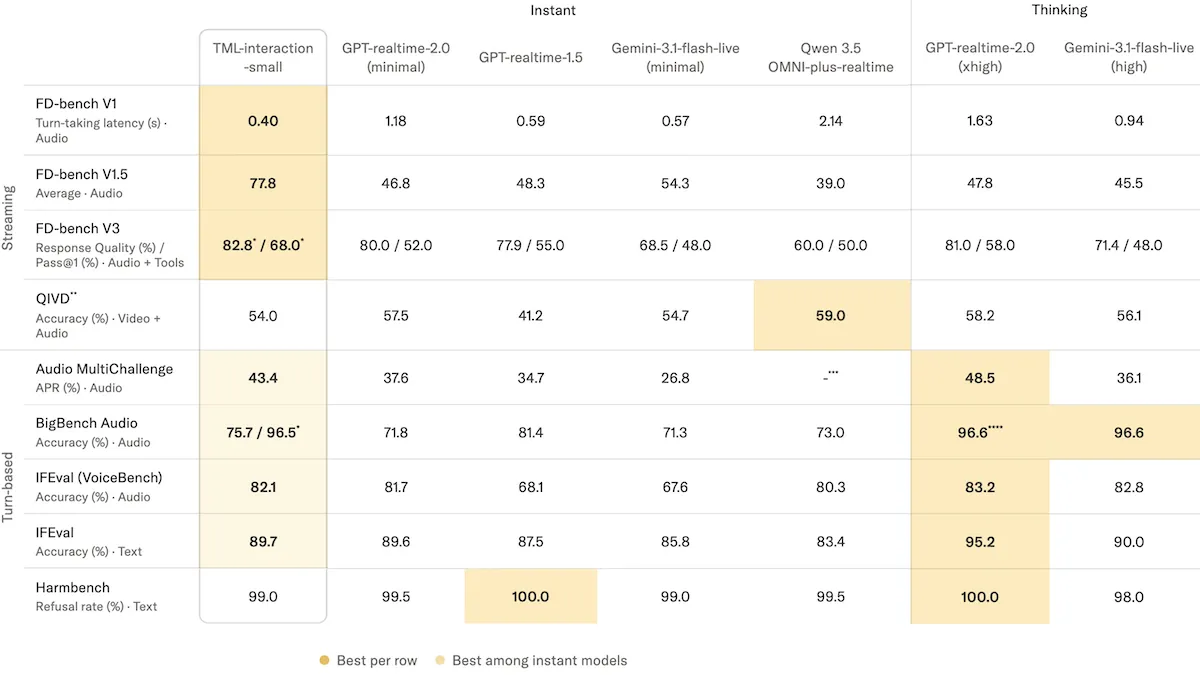
Performance: In Thinking Machines Lab’s tests, TML-Interaction-Small outperformed other voice models on benchmarks that evaluate interactivity but trailed GPT-Realtime-2’s strongest reasoning mode on tests of intelligence.
- On FD-bench V1, which measures audio latency in conversational turns, TML-Interaction-Small responded in 0.40 seconds, significantly faster than Gemini-3.1-flash-live-preview set to minimal reasoning (0.57) and GPT-Realtime-2 set to minimal reasoning (1.18 seconds).
- On FD-bench V1.5, which gauges a model’s ability to manage interruptions, interjections such as “uh huh,” and foreground versus background speech, TML-Interaction-Small achieved 77.8 average quality, well above GPT-Realtime-2 set to xhigh reasoning (47.8 average quality) and Gemini-3.1-flash-live-preview set to high reasoning (45.5 average quality).
- On Audio MultiChallenge, which tests reasoning and following instructions in multi-turn audio dialogue, TML-Interaction-Small achieved 43.4 percent APR (average pass rate, the share of conversations in which the model satisfied all criteria), behind GPT-Realtime-2 set to xhigh reasoning (48.5 percent APR) but ahead of Gemini-3.1-flash-live-preview set to high reasoning (36.1 percent APR).
- On BigBench Audio, a test of audio reasoning, TML-Interaction-Small achieved 96.5 percent accuracy with its background model activated, slightly below GPT-Realtime-2 set to high reasoning and Gemini-3.1-flash-live-preview set to high reasoning (tied at 96.6 percent accuracy).
Behind the news: TML-Interaction-Small, which arrives roughly 15 months after Mira Murati founded Thinking Machines Lab, promises to be the company’s first public model. The startup shipped a fine-tuning API called Tinker in October. This year, four other companies have launched models that listen, speak, and see videos or images in real time, and handle interruptions gracefully: OpenBMB open-sourced the 9-billion-parameter MiniCPM-o 4.5 in February, Google launched Gemini 3.1 Flash Live and Alibaba launched Qwen3.5 Omni in March, and OpenAI launched GPT-Realtime-2 in May.
Why it matters: Multimodal models often make users wait a second or more before responding, like GPT-Realtime-2, or they don’t respond to cues appropriately. Models that listen, see, and respond in real time open up interactions that turn-based systems can’t support like, say, coaching athletics or monitoring surgery. Of such models whose sizes are disclosed, TML-Interaction-Small is the largest to be trained specifically for interactive performance — 276 billion parameters versus 9 billion for MiniCPM-o 4.5, the most architecturally similar competitor whose parameter count is publicly known. Thinking Machines Lab said it has larger pretrained interaction models but can’t yet serve them fast enough for real-time interaction, and it plans to release them later this year.
We’re thinking: It’s worth noting how TML-Interaction-Small’s architecture differs from the approach taken by Vocal Bridge, an AI Fund portfolio company that we covered previously. While TML-Interaction-Small’s foreground and background models are jointly trained, Vocal Bridge takes an orchestration approach: A real-time voice model uses tool calls to defer heavy queries to a separate reasoning model and weaves its output back into the conversation. The upside is flexibility, since any real-time model can be paired with any reasoner, no training required. The downsides are that latency is bounded by the underlying API, the system is fundamentally turn-based, and handoffs between foreground and background are orchestrated rather than learned.

Cybersecurity Alarms Grow Louder
An AI-generated script to bypass two-factor authentication signals a dawning era of industrial-scale cyberattacks, according to a Google report
What’s new: Hackers used a large language model to identify a previously unknown vulnerability that made it possible for them to commandeer a widely used web administration tool, security researchers at Google reported. The researchers believe a criminal planned to use the technique on a large scale, and its discovery thwarted a broader attack. Their study outlines a variety of cybersecurity threats posed by the steady advance of large language models.
How it works: The Google team identified several ways in which large language models are making it faster and easier to execute cyberattacks. LLMs have aided cyberattacks before, and Anthropic recently warned that its Claude Mythos Preview model can find previously unknown vulnerabilities, but the report offers a catalog of up-and-coming approaches.
- Morphing malware: LLMs can generate malware that evades detection by changing elements of its code. Such programs include a so-called mutation engine that, every time they replicate or infect a new system, rewrite their own decryption routines, swap commands for alternatives that accomplish the same results, add nonfunctional subroutines, and so on without changing their functions. This approach can evade antivirus detection while keeping malicious payloads intact, increasing the danger of attacks that steal data, install backdoors, or encrypt files.
- Identifying logical flaws: Unlike tools typically used by cybersecurity professionals to find bugs in code, which often work by finding known patterns or bombarding it with random data until it breaks, LLMs can reason about what code is intended to do and apply that reasoning to identify logical flaws. This capability can discover vulnerabilities that are invisible to the usual tools and would require a focused review by human experts to find.
- Obfuscation networks: Threat actors often orchestrate ad hoc sets of routers, servers, and specialized technology to hide their points of origin, cover their tracks, and bypass defenses. AI-powered tools can direct malicious traffic through multiple compromised intermediary servers while avoiding patterns that would alert typical security monitors.
- Insecure AI infrastructure: AI infrastructure itself is becoming an attractive target for hackers. Beyond using AI to mask attacks, attackers increasingly target AI tools, models, and accessory software as entry points into networks. Compromising insecure components gives attackers a foothold to spread deeper into systems and steal data, deploy ransomware, or disrupt operations.
Behind the news: Security personnel and policy makers are reviewing defenses and governance measures in light of Claude Mythos Preview. Researchers at the cybersecurity firm Calif used that model to penetrate Apple’s famously sturdy security. Calif brought the exploit to Apple, which is working on a patch. Meanwhile, the United Kingdom-backed AI Security Institute (AISI) reported that Claude Mythos Preview and OpenAI’s GPT-5.5 could reliably execute attacks that would be expected to take humans 3 hours — substantially longer than their previous forecast of 1 hour. (At its debut, Claude Opus 4.6 was able to execute attacks that take people 30 minutes.) AISI’s tests limited the models to 2.5 million output tokens. When they allowed the models to use more tokens, the models were able to execute attacks that would take human attackers longer.
Why it matters: Google’s findings point to a widening gap between the ability of LLMs to find security vulnerabilities and widely used security methods. The report’s description of automated, industrial-scale attacks implies that next-gen LLMs may be able to exploit bugs faster than cyber teams can implement patches. Its findings may spur further federal scrutiny and complicate both regulatory and commercial efforts, as AI is both a defensive and an offensive tool as well as a prime target of attacks.
We’re thinking: Experts who have used Claude Mythos Preview confirm that it’s a clear advance for both security threats and defenses. We’re optimistic that the current round of patches will make networks more secure, and the lessons learned will contribute to safe roll-outs of further AI advances. Beyond that, software developers will need to devote more attention to proactive defensive research so they discover vulnerabilities before threat actors do.
Toward Agent Benchmarks That Reflect Human Work
AI agents seem to be increasingly capable of performing economically valuable tasks, but current benchmarks measure this capability only narrowly.
What’s new: Zora Z. Wang and colleagues at Carnegie Mellon University and Stanford University mapped examples drawn from agent benchmarks to statistics that represent U.S. labor. The mapping revealed a mismatch between the tests, which generally emphasize software development, and the more varied work most people do.
Key insight: Engineers tend to describe benchmark examples in technical terms, like “implement bubble sort,” while economists describe work activities using standardized descriptions like “Write, update, and maintain computer programs or software packages to handle specific tasks such as tracking inventory, storing or retrieving data, or controlling other equipment.” Work is also described in terms of skills necessary to do a job, such as “working with computers.” A large language model can translate among these languages. This capability makes it possible to compare the relative distributions of benchmark examples and work activities and skill.
How it works: The authors collected a representative selection of more than 10,000 examples drawn from 43 agent benchmarks, such as SWE-bench and WebArena. The authors built two taxonomies based on the U.S. government’s O*NET: (i) occupations (including 5,806 computer-based work activities) and (ii) 41 related skills.
- They retrieved the number of people employed in the U.S. and median wages data for each occupation and calculated the total number of workers and capital (employment multiplied by wages) associated with each occupation and skill.
- They used Claude 3.5 Sonnet to match the benchmark examples to all relevant computer-based work activities and skills (matching, for instance, the benchmark example “implement bubble sort” to the work activity “write, update, and maintain computer programs . . . ” and the skill “working with computers”).
- To limit their expenses, they randomly sampled batches of five examples at a time from each benchmark and mapped them to work activities and skills. When the total coverage in either taxonomy increased by less than 0.1 percent, they stopped. In practice, this meant that, if the benchmark contained less than 300 examples, they included all of them; for most other benchmarks, they sampled roughly 300 examples.
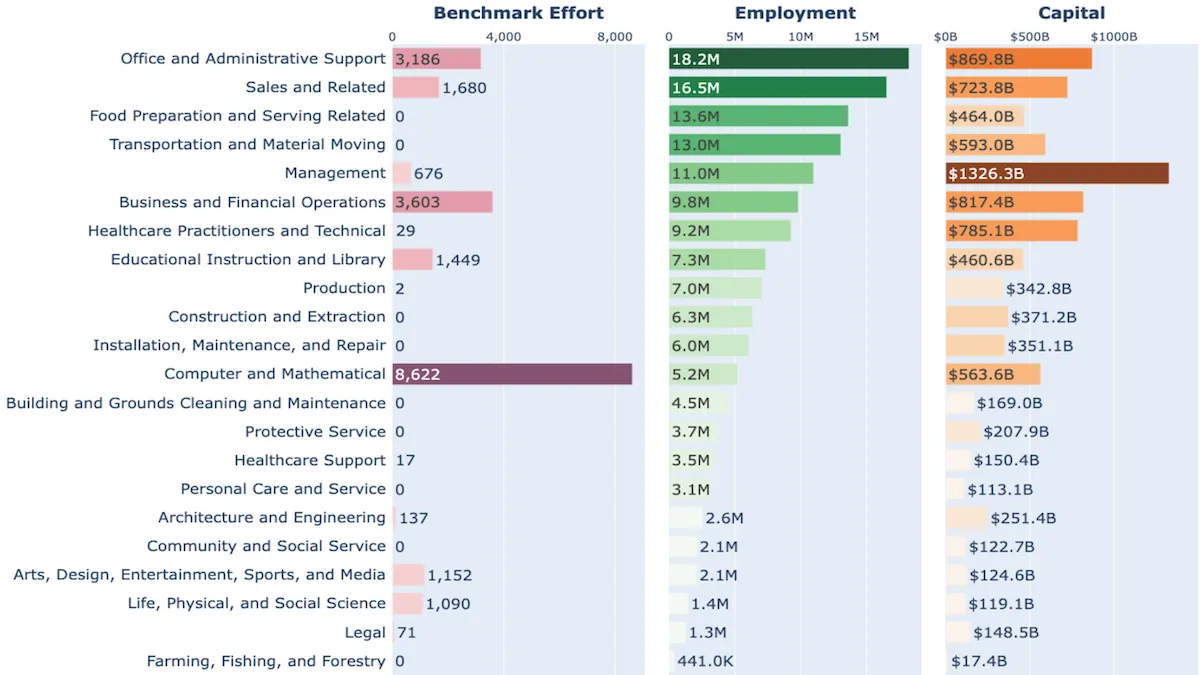
Results: The mapping showed that agent benchmarks largely measure performance in software engineering, which is distinctly different from the distribution of broader employment and capital within the job market.
- The benchmarks focus much more on “computer and mathematical” occupations (8,622 examples) than “office and administrative support” (3,186 examples) and “management” (676 examples). In comparison, the U.S. employs significantly fewer employees in “computer and mathematical” professions (5.2 million employees) than “office and administrative support” (18.2 million) and “management” (11 million). Similarly, U.S. employers pay “computer and mathematical” professionals a total of 563.6 billion dollars a year, hundreds of billions of dollars less than “office and administrative support” ($869.8 billion) and “management” ($1326.3 billion).
- Each benchmark covered less than 50 percent of all work activities and less than 60 percent of all skills. The benchmark that best covered both categories is GDPval, which encompassed 47.8 percent of work activities and 58.5 percent of skills. All benchmarks put together covered 56.5 percent of work activities, though they covered 85.4 percent of the authors’ 41 skill categories.
Why it matters: Agents have rapidly boosted productivity in software engineering, and they could do the same for other occupations that make up a large share of the economy. Identifying the gap between agent benchmarks and human labor distribution highlights untapped opportunities. Building agents for administrative, financial, and managerial sectors could yield higher economic value and help a larger portion of the workforce.
We're thinking: It makes sense that current benchmarks of agentic performance focus on software engineering — agentic coding is on fire! In some ways, software engineering is an incubator for applying agentic AI to other kinds of work, and we trust that benchmarks for measuring performance in broader work activities will come in due course.