
Dear friends,
We’ve been working on AI Andrew, an AI companion shaped by my personality. I invite you to try it out!
Many people are trying to understand what AI means for their work, learning, and careers. I’ve frequently enjoyed conversations with people on these topics. If you’d like to have a conversation on this, you might find AI Andrew can be a helpful thought partner and maybe even a friend — someone you can speak with about AI concepts, project ideas, career decisions, and whatever else is on your mind.
My team has been iterating on AI Andrew for many months, using an error analysis process to find circumstances where it says things that I would not say and debug our agentic harness to try to close the gap. My communication style has been shaped over the years by thousands of interactions. I’d never before tried to codify this in an agentic workflow. This turned out to be hard and is still a work in progress.
Reflecting on my beliefs about how to communicate has been an interesting exercise. I believe in:
- Respect for the individual. I hold a lot of respect for pretty much everyone I talk to, at any experience level or stage of life. I hope that comes through whenever I communicate.
- Celebrating wins. Many people have wins, large (like a new job or relationship) and small (like a piece of code that finally worked). I love hearing about and celebrating your wins!
- Empathy for what’s important to you. I want to help others realize their dreams. It is important to me that your dreams — not anyone else’s dreams for you — be the focus. Subject to ethical behavior, where I will respectfully push back if I see an issue, I’d like AI Andrew to support your goals, too.
- Technical precision. As a technology leader, I’m committed to speaking accurately about technical and scientific matters.

- Expressing opinions with carefully calibrated confidence. If I’m unsure of what to say, I try to ask a question rather than make a statement. In our error analysis, we found that many LLMs were overly eager to give advice despite lacking context. In real life, I try to give advice only when I’m fairly confident that it’s sound (like “please consider technology X!”). Otherwise, I would rather ask a question that supports the other person in arriving at a good answer (“What do you think about applying technology X?” or “What do you think is the best technology to apply here?”). This approach takes advantage of their context and mine to help them arrive at a better decision, rather than giving excessive weight to the limited context I have about their situation.
I am still learning how to have better conversations that support others in pursuit of their goals. We used a large mix of techniques in our harness, including RAG and many other tools, a mix of small and large models, guardrails, extensive evals, short- and long-term memory, and offline agentic loops that automatically propose improvements to the system.
To be clear, AI Andrew still has gaps! For example, an internal tester recently got it to hallucinate having climbed mountains that, sadly, I have not climbed, and it also occasionally gives advice that I question. Nonetheless, many users have reported gaining insights from talking to AI Andrew, and I hope you will find it (him?) a friendly companion that you can speak with about both personal and professional matters.
If you want to try it out, please tell me (in avatar form) what’s on your mind!
Keep building,
Andrew
A MESSAGE FROM DEEPLEARNING.AI

Go beyond using LLMs to understanding how they work! In Transformers in Practice, you’ll learn how transformers generate text, process context, and run efficiently using attention, KV caching, and quantization. Earn a certificate as a DeepLearning.AI Pro member. Enroll Now
News
U.S. to Evaluate Upcoming Models
The U.S. government said it will evaluate cutting-edge models before they’re available to the public, a sharp reversal of the White House’s earlier hands-off policy.
What’s new: The National Institute of Standards and Technology (NIST), an office of the U.S. Department of Commerce, announced that a new multi-agency task force will assess national-security risks posed by AI models prior to their deployment. Leading U.S. AI companies agreed to submit models for evaluation prior to release. In addition, the White House is considering an executive order that would require AI models to gain approval before they can be deployed.
How it works: NIST said the tests will focus on demonstrable risks to cybersecurity, biosecurity, and chemical weapons. The administration did not disclose details of its agreements with AI companies or any controls it expects to impose on models in light of test results.
- Models will be evaluated by Testing Risks of AI for National Security (TRAINS), a group overseen by the Center for AI Standards and Innovation (CAISI), a division of NIST. TRAINS differs from other NIST groups that have been disclosed insofar as it is designed for rapid response and draws on multiple federal agencies, including the Departments of Commerce, Defense, Energy, and Homeland Security; the National Security Administration and the National Institutes of Health.
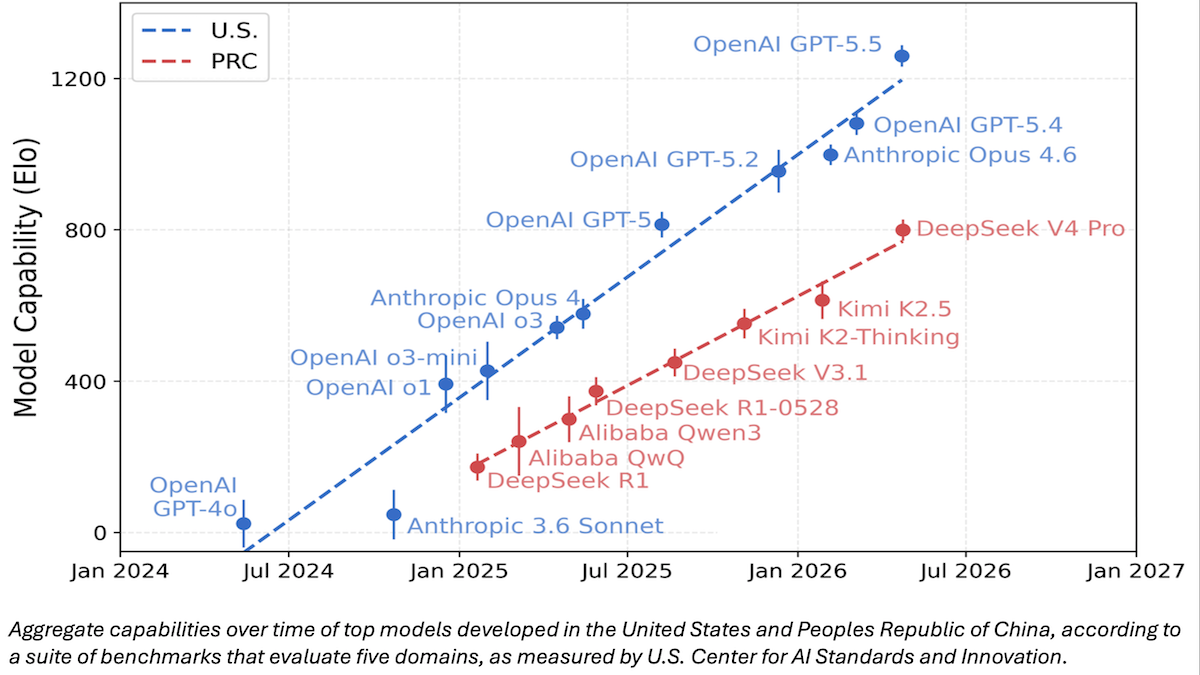
- TRAINS has not disclosed the benchmarks it intends to use. However, NIST has shared CAISI’s earlier comparison of DeepSeek V4 Pro with other large language models. CAISI ranked model capabilities according to an aggregate of nine widely used public benchmarks that span cybersecurity, coding, mathematics, natural sciences, and abstract reasoning plus an internal test called PortBench (porting command-line interface tools between different programming languages).
- Google, Microsoft, and xAI agreed to provide models that have limited or absent guardrails, and Anthropic and OpenAI had agreed to similar terms in 2024. The agreements will enable collaborative private-public research into evaluations of capabilities and risks, as well as mitigation of risks.
Behind the news: The abrupt policy change marks a major departure from the Trump Administration’s focus on removing Biden-era regulatory barriers to AI innovation. It comes roughly one month after Anthropic attracted the government’s attention by announcing that its Claude Mythos Preview model, which is not yet widely available, could exploit vulnerabilities in widely used software.
- Immediately after taking office in January 2025, President Trump assigned three key advisors to craft an AI Action Plan that would “sustain and enhance America’s global AI dominance” by suspending or eliminating regulatory policies created by President Biden. In 2023, the Biden Administration had issued an executive order that required developers to notify the government when they train a model whose processing requirements corresponded roughly to 1 trillion parameters.
- In March 2026, Anthropic tried to limit military use of Claude for surveillance and autonomous weapons. The White House rejected any limitations and banned the model from military use entirely.
- The following month, Anthropic announced that Claude Mythos Preview could autonomously exploit vulnerabilities in major operating systems and applications. The company had shared Mythos with 50 organizations that are using it to detect and patch their software.
- Last week, the White House said it opposes the company’s plan to expand the preview to another 70 organizations, citing concerns about national security and whether Anthropic has access to sufficient computational power to serve both existing Mythos users and the government. The company has not stated whether it intends to challenge the administration’s authority to limit the distribution of the preview model.
Why it matters: The White House’s shift from laissez-faire to pre-release scrutiny of AI models reflects a dawning reality that AI models have become powerful enough to pose immediate risks to national security. Requiring AI developers to test advanced models prior to public availability could give the government advance warning of potential issues and motivate AI developers to manage them proactively. It would also enable the government to decide which models are fit for wider distribution, and which must be withheld or altered (for reasons that may not be transparent). AI companies aren’t yet required to submit new models for government testing, and those who have agreed to do so have agreed voluntarily. However, officials are considering an executive order that would make such testing mandatory.
We’re thinking: A standardized battery of benchmark tests, applied comprehensively and according to consistent procedures, would be beneficial to the AI industry, but we think the right way to come up with these tests would be via the free market, rather than be imposed by government. Further, requiring government tests ahead of release would slow down U.S. developers, putting them at a competitive disadvantage relative to their peers in other countries, and potentially help them thwart open-source competitors through regulatory capture.
OpenAI Challenges Speech-to-Speech Leaders
An update of OpenAI’s speech-to-speech model lets developers tune the tradeoff between speed and reasoning.
What’s new: OpenAI introduced three new audio models in its Realtime API. GPT-Realtime-2 is a speech-to-speech model with configurable reasoning effort. GPT-Realtime-Translate translates speech between more than 70 input languages and 13 output languages, and GPT-Realtime-Whisper transcribes speech into text.
- Input/output: GPT-Realtime-2 text, audio, image in (up to 128,000 tokens), text, audio out (up to 32,000 tokens, 1.12 seconds to first audio at minimal reasoning, 2.33 seconds at high reasoning); GPT-Realtime-Translate audio in (up to 16,000 tokens), audio out (up to 2,000 tokens); GPT-Realtime-Whisper text audio in (up to 16,000 tokens), text out (up to 2,000 tokens)
- Knowledge cutoff: September 30, 2024
- GPT-Realtime-2 features: Five levels of reasoning effort (minimal, low, medium, high, xhigh), parallel tool calls, narration of tool calls, optional preambles, graceful handling of problematic input, tone (attitude) control, function calling
- GPT-Realtime-2 performance: Tops Scale AI’s Audio MultiChallenge audio-output leaderboard and Artificial Analysis Conversational Dynamics, tied for third on Artificial Analysis Big Bench Audio
- Availability: Via OpenAI Realtime API
- Prices: GPT-Realtime-2 $32/$0.40/$64 per million input/cached/output audio tokens, $4/$0.40/$24 per million input/cached/output text tokens, $5/$0.50 per million input/cached image tokens; GPT-Realtime-Translate $0.034 per minute; GPT-Realtime-Whisper $0.017 per minute
- Undisclosed: Parameter counts, architectures, training data and methods
How GPT-Realtime-2 works: GPT-Realtime-2 handles audio in and audio out as an end-to-end process — including reasoning — rather than separate speech-to-text, text-generation, and text-to-speech steps.
- An API parameter sets the reasoning effort. Low is the default, chosen to minimize latency for live conversation. Higher reasoning effort increases latency and consumption of reasoning tokens.
- During tool calls, the model can narrate its work in progress using spoken phrases like “checking your calendar” or “looking that up now.” Optional preambles like “let me check that” can precede response to prompts, so users can track progress while the model reasons.
- When it can’t complete a request, the model alerts users via phrases like “I’m having trouble with that right now” instead of remaining silent.
GPT-Realtime-2 performance: GPT-Realtime-2 led some independent benchmarks for conversational dynamics and multi-turn instruction following, but it trailed on the Artificial Analysis Speech Reasoning leaderboard. The time required to generate audio ranged from 1.12 seconds at minimal effort to 2.33 seconds at high effort, which yields the model’s best reasoning scores — generally slow for real-time interactions, which benefit from latency lower than 500 milliseconds.
- On Artificial Analysis Big Bench Audio (answering questions drawn from the Big Bench benchmark), GPT-Realtime-2 set to high reasoning tied Google’s Gemini 3.1 Flash Live Preview set to high reasoning (96.6 percent), behind Step-Audio R1.1 Realtime (97.6 percent) and Grok Voice Think Fast 1.0 (97.1 percent). Set to minimal reasoning, GPT-Realtime-2 dropped to 71.8 percent.
- On Artificial Analysis’s Conversational Dynamics (a weighted average that tests the ability to manage taking turns, pausing, interruptions, and brief interjections such as “uh-huh”), GPT-Realtime-2 set to minimal reasoning led with 96.1 percent. However, set to high reasoning (95.3 percent), it lagged GPT-Realtime-1.5 and GPT Realtime Mini (tied at 95.7 percent).
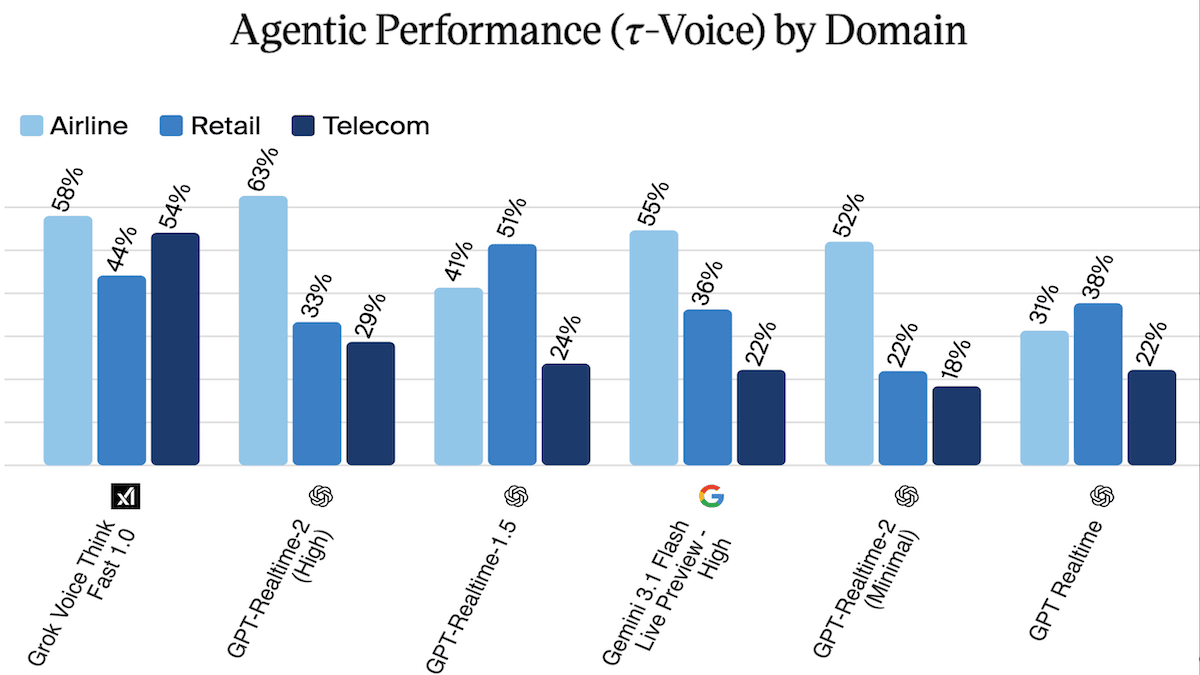
- On 𝜏-Voice (agentic performance in three customer-service domains), GPT-Realtime-2 led the airline domain with 63 percent, according to Artificial Analysis. But considering all three domains, GPT-Realtime-2 (39.8 percent) fell behind Grok Voice Think Fast 1.0 (52.1%) but ahead of Gemini 3.1 Flash Live Preview set to high (37.7 percent).
- On the Scale AI Audio MultiChallenge Audio Output leaderboard, which evaluates four conversational criteria (instruction retention, inference memory, self-coherence, and voice editing) in multi-turn spoken dialogue, GPT-Realtime-2 set to xhigh reasoning placed first (48.45 percent average pass rate, the share of conversations in which the model satisfies every criterion), a significant jump from its predecessor GPT-Realtime-1.5 (34.73 percent average pass rate). However, Scale AI has not yet tested Grok Voice Think Fast nor Step-Audio R1.1 Realtime.
Yes, but: The two models ahead of GPT-Realtime-2 on the Artificial Analysis Speech Reasoning leaderboard are also faster.
- Step-Audio R1.1 Realtime takes 1.51 seconds to generate its first audio output and Grok Voice Think Fast 1.0 takes 1.25 seconds, versus 2.33 seconds for GPT-Realtime-2 at high reasoning effort.
- With reasoning set to xhigh, GPT-Realtime-2’s overall pass rate on the Scale AI Audio MultiChallenge is below 50 percent, which suggests that reliable multi-turn spoken dialogue remains challenging for current models.
Why it matters: Voice agents generally have focused on relatively simple interactions because reasoning often comes at the cost of a snappy response. GPT-Realtime-2 offers not only high performance but also control over that tradeoff (minimal reasoning for faster turn-taking, xhigh for interactions that can wait). This flexibility expands the range of tasks voice agents can handle without resorting to text processing.
We’re thinking: It's exciting to see that GPT-Realtime-2 implements preambles similar to the pre-responses we described here!

China Nixes Meta-Manus Tie-Up
China shut down Meta’s attempt to acquire agentic technology that originated within its borders, a blow to further technical interchange and investment between China and the U.S.
What’s new: China’s cabinet-level regulator in charge of economic planning and development blocked Meta’s proposed acquisition of Manus, a Singapore-based startup that was founded in China and offers a popular AI agent. Meta and Manus unwound the deal, which was worth as much as $2.5 billion. Beyond quashing Meta’s plans to offer agentic products and features, the action upended an emerging strategy for launching AI startups built in China.
How it works: Meta’s purchase of Manus was viewed as a sign that Manus, having relocated to Singapore and closed its business in China, had maneuvered itself successfully beyond Bejing’s purview. But the government asserted its authority over strategically important technology developed in China by Chinese engineers. Startups founded in China responded by rolling back plans to move elsewhere to seek international investments or partnerships.
- The China-based company Butterfly Effect developed a general-purpose agent that completes long-running tasks with minimal user input and guidance. In early 2025, it launched Manus as an invitation-only beta and quickly attracted users as well as investments from major Chinese investors and Silicon Valley venture capitalists. The company relocated to Singapore in July. As the year ended, Manus reported $100 million in annual recurring revenue that was growing at 20 percent monthly.
- In December, Meta announced the deal to acquire Manus and began integrating Manus technology into its own AI chatbots and offerings on Facebook, Instagram, and WhatsApp. It also announced plans to continue operating Manus as an independent business.
- The following month, China’s National Development and Reform Commission (NDRC) opened a security review, citing concerns over potential transfers of data and foreign ownership of services that operate in China. In April, the agency said it will examine foreign investment in domestic AI companies much more closely, particularly to curb U.S. investment in and acquisition of technology developed in China. It went on to block the Meta-Manus deal.
- The move has created a chilling effect for China’s tech founders and investors, for whom the “Singapore strategy” no longer gives them the flexibility to raise money from foreign investors and explore partnerships with companies in and outside the region. They are cancelling plans to move abroad, pursue acquisitions, or raise money from U.S. and European sources.
Behind the news: For more than a decade, the U.S. and China have viewed advanced technology as a strategic arena tied to economic influence, military power, and national security. Earlier disputes over espionage, intellectual property, and technology transfer escalated into sweeping government intervention. The U.S. blacklisted the Chinese communications-technology company Huawei as a security risk in 2019 and imposed increasingly stringent export controls on semiconductors beginning in 2022. Meanwhile, Beijing set conditions on foreign companies seeking access to the Chinese market and imposed rules to reduce its reliance on Western technology. Numerous Chinese startups have attempted to sidestep the superpower rivalry by incorporating in Singapore and elsewhere. China’s decision to block the Meta-Manus deal strikes a blow to that strategy.
Why it matters: The tightening of China’s control over AI startups raises tensions amid an already tense situation between China and the U.S. This week, leaders of the two countries will meet to discuss geopolitical concerns, including AI. An agreement may permit technology and ideas to flow more easily between the two countries (and from China to Singapore and elsewhere in the region). But an ongoing stalemate could drive both countries to withdraw further from free exchange and harden defenses of their own national security and economic interests.
We’re thinking: Beijing’s regulators appear to be asserting authority over any strategically important company whose technology, talent, or operations originated in China. That would sharply narrow the path of founders and investors who hope to attract Western capital or pursue international acquisitions.

AI Mammogram Diagnosis Under Real-World Conditions
Introduced in 2020, Google’s AI system for detecting breast cancer in mammograms still hasn't been used to diagnose current patients. Two studies evaluated how well it would integrate with protocols at UK clinics.
What’s new: In a test on real-world data, Google’s breast-cancer detection system identified slightly more cancers with fewer false positives than examinations by the first of two expert doctors. More significantly, it identified a quarter of cancers that human doctors missed but became apparent later. In a companion study, the system performed about as well as a second expert (who considered the first’s opinion). However, some doctors reported distrust in the system’s output. The studies were conducted by Christopher J. Kelly, Marc Wilson, and colleagues at Google, Imperial College London, University of Surrey, Royal Surrey National Health Service Foundation Trust, and several National Health Service Breast Screening Centres.
How it works: Google’s system uses three convolutional neural networks that were trained on a mammography database to produce embeddings, determine potential cancerous regions, and classify the probability of cancer.
Tests and results: In the two studies, the AI system helped to identify more cancers, and to identify them faster and earlier, in a typical UK diagnostic process.
- A retrospective test evaluated the system’s ability to detect cancers based on 116,000 mammograms of women of ages 50 to 70 taken at five hospitals in 2016. The authors selected scans of the same women taken up to 39 months apart and compared diagnoses by their system versus a human expert. It achieved a sensitivity of 0.541 (the proportion of positives correctly identified), significantly higher than the 0.437 achieved by the first of two human evaluations. Its specificity was 0.943 (the proportion of negatives correctly identified) compared to the human rate of 0.952 — lower, but statistically equivalent. The AI system also successfully identified 25 percent of cases that humans had missed initially but became apparent three years later.
- Considering 46,000 scans, the authors simulated what it would be like if the system were to replace the second of two human evaluators. The system achieved slightly better sensitivity and specificity, indicating that using AI for the second evaluation could save time while gaining accuracy. According to the clinics’ protocols, in cases where cancer was detected or the AI disagreed with the human, the cases were sent to an arbitration panel for a final determination. The AI sent 1,800 more cases to arbitration (an absolute increase of 4 percentage points; 5,300 total). Assuming that arbitration took five times as much human effort as reading does, the authors concluded that, despite sending more cases to arbitration, the system would reduce human effort by roughly 40 percent.
- A live test evaluated the system’s ability to integrate with the real-world National Health Service infrastructure. The system labeled high or low risk around 9,250 fresh scans of women of ages 50 to 70 taken at 12 clinics during a few months in 2023 and 2024. (The test did not affect patient care. Patients were diagnosed by doctors in the usual way, and neither doctors nor patients were informed of the AI system’s diagnosis.) The system was much faster than human doctors, achieving a median processing time of 17.7 minutes from screen to interpretation compared to more than two days for the first of two human evaluations. The authors followed up three months later to determine the ground truth of whether a patient had cancer. As in the retrospective study, the system achieved better sensitivity than the first human evaluation and lower but statistically equivalent specificity.
Behind the news: Efforts to use AI for breast cancer detection began with earlier computer-aided detection (CAD) systems in the 1990s and 2000s, but the field accelerated in the mid 2010s as deep-learning models trained on large mammography datasets began outperforming older methods. In 2020, researchers at Google showed that an AI system could match or exceed expert radiologists in screening mammograms while reducing both false positives and false negatives. In late 2022, Google licensed the system to iCAD, which offers a breast-imaging platform, for deployment in real-world clinics. In 2023, Google and iCAD expanded their partnership into a 20-year worldwide commercialization agreement aimed at using Google’s AI as an independent “second reader” of 2D mammography. The partnership currently aims to secure regulatory approval for potential deployment in breast-cancer screening systems that use double-reading workflows.
Why it matters: Around 2.3 million women are diagnosed with breast cancer annually worldwide, and 760,000 don’t survive. Early diagnosis is critical. Yet the diagnostic system is overburdened. In the UK, for instance, a consultant breast radiologist has only four hours available weekly to look at the 5,000 scans they must read annually to maintain their certification. These studies show that AI can ease diagnostic workloads and improve outcomes by helping to prioritize scans or serving as a default co-reader. But they also highlight a need to build trust in the technology among doctors. This may require educating physicians in how AI systems work and making the systems’ output more explainable.
We’re thinking: As AI systems find their way into medicine, they raise important questions about the steps needed to build trust in the technology, and what checks and balances will yield the best outcomes. Developers can talk directly with doctors about what they need to gain trust in an AI system's output.