
Dear friends,
Should there be a Stack Overflow for AI coding agents to share their learnings with each other?
Last week, I wrote about the new Context Hub (chub), a CLI tool to provide API documentation to coding agents. Coding agents built using LLMs that learned from old code examples often use incorrect or outdated APIs. Chub addresses this by letting them access the latest documentation. I’ve been thrilled at the community enthusiasm for chub over the past week (over 5K github stars, growing usage, and community contributions of documentation). Thank you for your support!
A key part of the vision for chub was getting feedback from coding agents that can help other agents. Specifically, if an agent obtains a piece of documentation, tries it out, and discovers a bug, finds a superior way to use an API, or realizes the documentation is missing something, feedback reflecting these learnings can be very useful for humans updating the documentation. Or perhaps someday for agents updating the documentation.
Moltbook, a Reddit-like social network for agents, grew rapidly with many OpenClaw agents using it, and Meta acquired it earlier this week. I found the conversations among AI agents speculating about all sorts of topics like their “souls” mildly entertaining. I think there’s room for a new type of social media for agents that’s focused on being useful in practical ways.

Stack Overflow has been a great service for developers. It has been a place where we can ask questions, answer questions, and upvote/downvote answers. It turned into a great source of training data for LLMs, and many developers now ask coding questions to LLMs rather than Stack Overflow. But I am inspired by Moltbook and Stack Overflow to think that it will be useful to let coding agents contribute their feedback on documentation so as to help other agents.
We’re still in the early stages of building this capability in chub. (If you want to use chub but don’t want your agent to contribute feedback, you can disable this by adding “feedback: false” to ~/.chub/config.yaml; see our github repo for details). My collaborators Rohit Prsad and Xin Ye and I are working on a custom agentic deep researcher to help us write more documentation. Together with community contributions, over the past week, we have grown the document collection from under 100 to almost 1000. I expect the feedback from coding agents will help to keep refining this documentation for the benefit of all coding agents.
Social sharing isn’t only for humans. It’s also for agents! As we navigate ways for many agents to learn from each other — being careful to provide strong safeguards for privacy and security — we will make both AI agents and the humans they serve better off.
Keep building!
Andrew
A MESSAGE FROM DEEPLEARNING.AI

In Agentic AI, taught by Andrew Ng, you’ll learn to design multi-step, autonomous workflows in raw Python covering four design patterns: reflection, tool use, planning, and multi-agent collaboration. Available exclusively at DeepLearning.AI. Enroll now!
News
GPT-5.4’s Higher Performance, Higher Price
OpenAI updated its flagship models, extending the ability to use tools and setting the state of the art on a handful of benchmarks, and priced them at the top of the market. Its coding and agentic abilities have enabled Codex, OpenAI’s competitor to Anthropic’s Claude Code, to leap ahead.
What’s new: GPT-5.4 comes in two variants, Thinking and Pro, both with an expanded context window relative to GPT-5.2. (Only two days elapsed between the launch of GPT-5.3 and GPT-5.4, and OpenAI offered no explanation.) GPT-5.4 models are trained to use computers natively and help agents find and use tools more efficiently, a capability called tool search.
- Input/output: Text, images in (up to 1,050,000 tokens), text out (up to 128,000 tokens)
- Architecture: Mixture-of-experts transformer
- Features: Tool use (Google search, Python code execution, file search, function calling), tool search, computer use, adjustable reasoning (low, medium, high, xhigh)
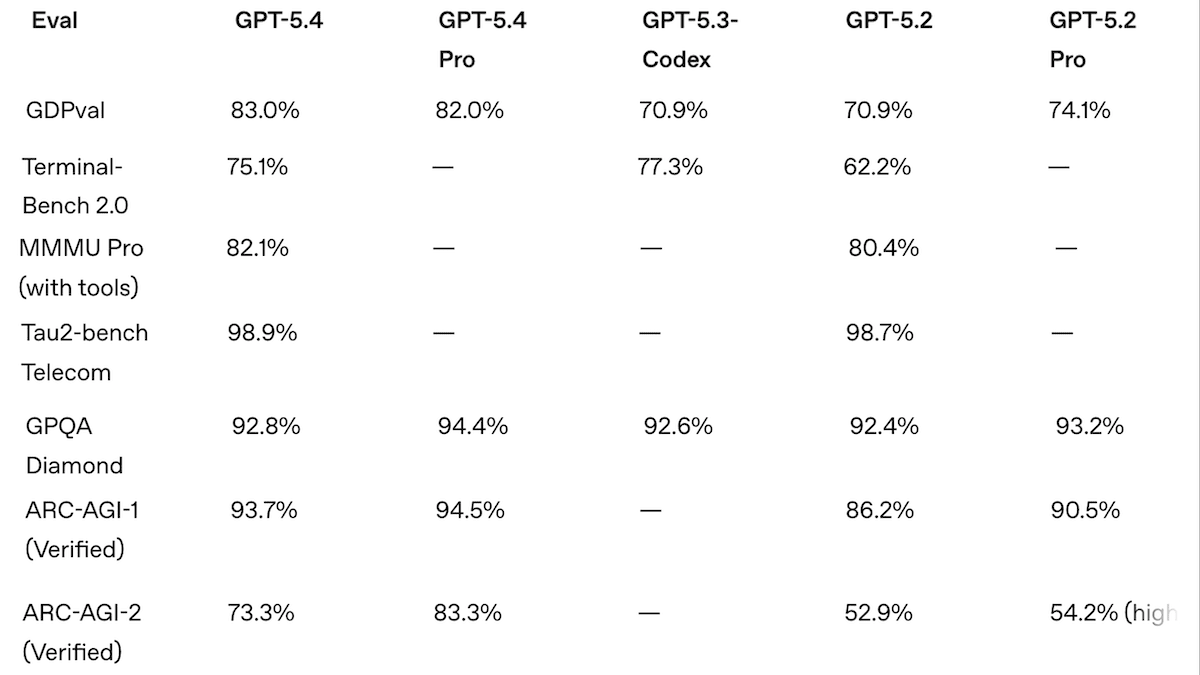
- Performance: In independent tests, GPT-5.4 Pro with xhigh reasoning achieved state of the art on GDP-Val-AA, BrowseComp, Terminal-Bench-Hard, SWE-Bench-Pro, and MCP Atlas; it’s just behind Gemini 3.1 Pro Preview on MMMU-Pro and Humanity’s Last Exam (without tools) and just behind Gemini 3 Deep Think on ARC-AGI-1 and ARC-AGI-2
- Availability/price: GPT-5.4 is available in ChatGPT via subscription at Plus, Team, and Pro tiers. Via API, GPT-5.4 is available for $2.50/$0.25/$15 per 1 million input/cached/output tokens, and GPT-5.4 Pro is priced at $30/$180 per 1 million input/output tokens.
- Knowledge cutoff: August 2025
- Undisclosed: Parameter count, architecture details, training methods
How it works: As is typical of closed models, OpenAI disclosed few details about how it built GPT-5.4 and GPT-5.4 Pro. The model is a sparse mixture-of-experts transformer pretrained on text, code, and images scraped from the web alongside licensed materials, user data, and synthetic data. It was fine-tuned via reinforcement learning on datasets that covered multi-step reasoning, solving problems, and proving theorems.
Performance: GPT-5.4 Pro leaped over GPT-5.2 Pro and Claude 4.6 Opus to achieve a number of state-of-the-art metrics in independent tests by Artificial Analysis. But even in OpenAI’s own tests, it underperformed Gemini 3.1 Pro Preview in several tasks and cost more to run the same tests.
- On the Artificial Analysis Intelligence Index, a weighted average of 10 benchmarks that focus on economically useful work, GPT-5.4 Pro set to xhigh reasoning nearly tied Gemini 3.1 Pro Preview with reasoning (57 points at a cost of $2,950 vs. 57.2 points at a cost of $892), but outperformed Claude Opus 4.6 set to max reasoning (53 points, $2,486), GPT-5.3 Codex set to xhigh reasoning (54 points, $1,650), and the open-weights GLM-5 (50 points, $547). It led three of the index’s 10 component benchmarks.
- GPT-5.4 Pro set to xhigh topped Artificial Analysis’ Coding and Agentic indices (subsets of the Intelligence Index devoted to each broad category), with scores of 57 and 69 points, topping Gemini 3.1 Pro Preview (56 points) and Claude Opus 4.6 (68 points).
- On ARC-AGI-2 visual logic puzzles, GPT-5.4 Pro set to xhigh (83.3 percent) came in ahead of Gemini 3.1 Pro Preview (74.0 percent) and fractionally behind Gemini 3 Deep Think (84.6 percent).
Why it matters: OpenAI’s GPT 5.4 has vaulted over Anthropic’s Claude — for the moment — to challenge Google’s Gemini for the top spot. OpenAI touts the GPT-5.4 family’s improved performance per token, but it still requires twice as many tokens as Gemini 3.1 Pro Preview to match the latter’s performance, and its higher efficiency is largely negated by its higher price. GPT-5.4 Pro is a state-of-the art coding model, and costs less than Claude Opus 4.6 to complete coding tasks. But Google’s ability to keep Gemini 3.1 Preview’s price low and overall intelligence high, along with its ability to process audio and video, remains a formidable obstacle for any AI company that aims to become the undisputed leader.
We’re thinking: GPT-5.4 ranks highest on benchmarks developed internally by OpenAI, as you would expect. But these metrics show that the models are built to solve hard problems in automating office work. GPT-5.4 Pro turned in impressive performance on GDPval (83 percent win or tie rate against professionals across knowledge-work tasks like writing legal briefs and customer-support conversations) and OSWorld-Verified (75 percent success rate on computer use tasks like navigating websites and updating spreadsheets from files, above the 72.4 percent human baseline). Given the high human costs of this work, GPT-5.4 Pro, even at xhigh reasoning, may turn out to be a bargain.
AI on Mobile Skyrockets
Downloads of mobile AI apps and resulting revenue are surging.
What’s new: The State of Mobile 2026 report by Sensor Tower, a market research firm, tracks the rapid growth of AI assistants, generative apps, and AI companions on smartphones. Last year, thanks to spending on AI apps, revenue from non-game apps exceeded gaming revenue for the first time, according to the firm’s analysis.
How it works: The authors evaluated the market for mobile AI in 2025. They estimated numbers of downloads, hours of use, and in-app revenue (but not advertising revenue) from the iOS App Store and Google Play based on proprietary data and data from developers. They did not obtain data from other app stores, so the report doesn’t reflect mobile activity in regions such as China, where users download apps mostly from stores run by domestic companies.
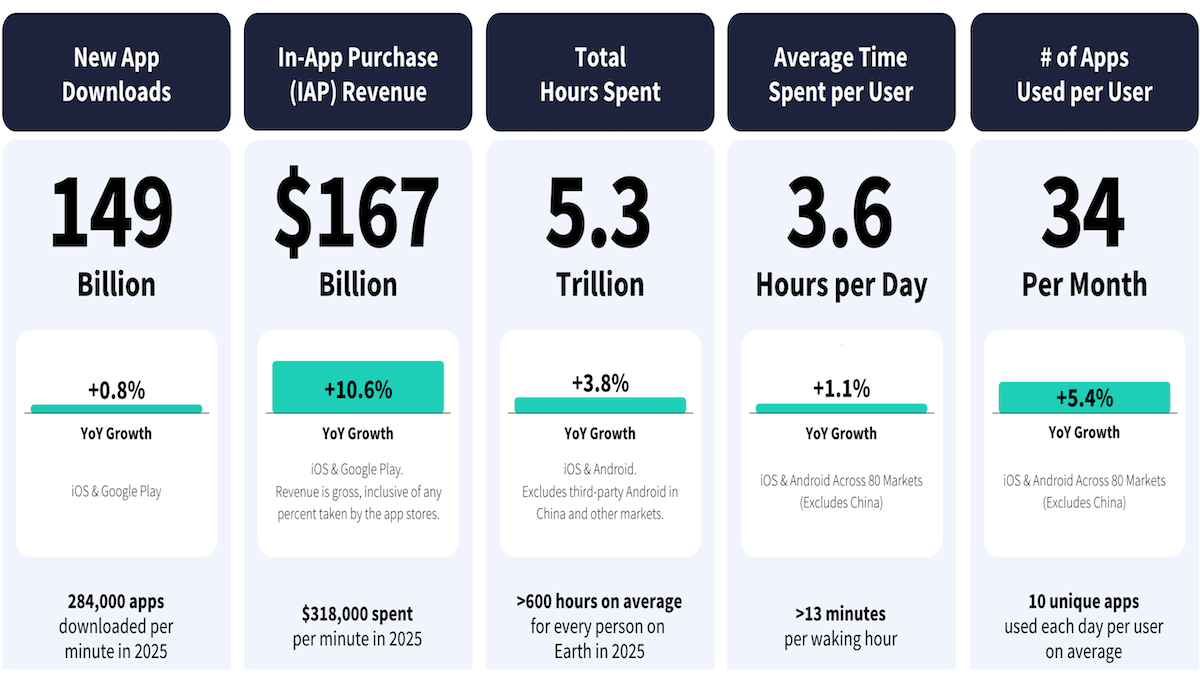
- Overview: Global revenue from AI-powered apps and downloads accelerated last year. Revenue tripled to more than $5 billion, while downloads doubled to over 3.8 billion.
- Leaders: The most-downloaded AI app, defined as one that uses AI for creative or generative tasks, was OpenAI ChatGPT followed by Google Gemini, DeepSeek, ByteDance Doubao, and AI-enhanced search engine Perplexity. OpenAI and DeepSeek accounted for almost 50 percent of global AI downloads, up from 21 percent in 2023, when Sensor Tower began tracking this category. Established tech companies like Amazon, Google, and Microsoft accounted for 30 percent of downloads in the past year, up from 14 percent in 2023. The long tail of AI startups made up the last 20 percent.
- Assistants versus generators: All of the top 10 most-downloaded apps were AI assistants. Nonetheless, generative apps like the Suno music generator and Bytedance’s Jimeng AI text-to-video app showed strong growth. The number of U.S. users of the top 10 AI assistants amounted to roughly 60 percent of the total population.
- Engagement: Users spent 48 billion hours in AI apps, roughly 3.6 times the total in 2024 and nearly 10 times the number of hours in 2023.
- Apps versus web: Around 110 million U.S. chatbot users — more than half — used AI exclusively via mobile apps, up from 13 million mobile-only users at the beginning of 2024. Another 34 million users of AI assistants gain access to them via both apps and the mobile web.
Behind the news: Mobile AI assistants are only a few years old, and user behavior is changing quickly. OpenAI introduced its first ChatGPT mobile app in May 2023. Today nearly every major AI assistant is available as an app. Earlier this year, Microsoft found that Copilot users behaved differently on mobile devices and at different times of day. For instance, mobile users were more likely to discuss health and fitness than work and productivity.
Why it matters: AI is becoming habitual for millions of users, not just when they’re working but also when they’re away from their desks and mobile devices are more handy than desktops. In that context, AI apps increasingly compete for time and attention directly with games, social media, and short-form videos. Both time and attention spent lead to more revenue and long-term use.
We’re thinking: The question whether AI-driven revenue will catch up to enormous capital expenditures has led to worries about an AI bubble. This blistering pace of growth in mobile AI revenue is encouraging!

AI Data Centers Go Off the Grid
Meta and OpenAI are among the tech companies that are building private power plants that will operate independently of regional grids to supply electricity for their massive buildout of AI data centers.
What’s new: Several off-grid power plants associated with data centers are planned or under construction in the United States, according to regulatory filings, permits, transcripts of conference calls with investors, and other documents, The Washington Post reported. Fueled primarily by natural gas, the plants will be connected directly to data centers, sidestepping the oversight and delays that come with grid connections. The Post’s report is based on a study by energy researcher Cleanview that identified 46 projects, 90 percent of them announced in 2025, to build private power plants that are “behind the meter,” meaning they supply electricity directly to a customer but also connect to the grid. Together they account for 30 percent of all planned data-center capacity in the U.S. Spurred by the White House, executives at Alphabet, Meta, Microsoft, OpenAI, Oracle, and xAI agreed to shoulder the costs of building power plants and upgrade the grid to soothe worries about rising electricity prices.
How it works: The names of the tech companies that are building their own power plants are largely obscure in the available documents. The projects, which will drive data centers that are expected to consume gigawatts of power, involve collaborations between tech companies, energy infrastructure builders, and/or local power companies. They’re being developed rapidly, in some cases using atypical generators, as conventional turbines are in short supply.
- Meta is building two private gas-fired plants in Ohio that will generate 400 megawatts, a project called Socrates, to drive a data center that will consume 1 gigawatt. Another Meta project in Texas will connect more than 800 small gas-fired generators to generate 366 megawatts for a 1-gigawatt data center.
- OpenAI and Oracle have a project in New Mexico called Jupiter. It will use large-scale natural gas generators to power a 1 megawatt data center. Jupiter is part of the companies’ broader data-center effort known as Stargate.
- A 1.8-megawatt data-center project in Wyoming will be powered by modified jet engines, each of which will produce 42 megawatts. The generators are designed by Boom Supersonic, an aerospace company partly owned by OpenAI CEO Sam Altman who also sits on its board of directors.
Behind the news: All the major tech companies have been scrambling to lock down access to electricity sufficient to support a data-center buildout that is projected to cost $5.2 trillion and consume 156 gigawatts by 2030.
- xAI bypassed the grid to power data centers in 2024, when the company built data centers in Memphis to house its Colossus and Colossus 2 supercomputers. The facilities are powered by a private collection of dozens of temporary, mobile gas turbines despite a ruling by the Environmental Protection Agency that they were being used illegally.
- Meta, in addition to building private power stations in the short term, is pursuing a long-term strategy to build nuclear power plants, which are scheduled to come online in the early 2030s. The company committed to help build new reactors and to purchase electricity from older reactors. These deals are expected to supply more than 6 gigawatts.
- Alphabet, Amazon, and Microsoft have entered into smaller agreements to obtain nuclear energy. Alphabet is working to reopen a disused nuclear plant in Iowa, Amazon invested in the reactor developer X-Energy, and Microsoft agreed to buy 10.5 gigawatts of new renewable energy capacity between 2026 and 2030 for an estimated $17 billion.
Why it matters: The rise of private power for data centers reflects a bottleneck as AI companies plan to increase their capacity faster than current energy suppliers can meet. It signals a shift in the ways AI infrastructure, power plants, and public utilities interact, with implications that go well beyond tech companies.
- Demand for AI caused electricity prices to rise at more than double the rate of inflation in 2025, according to Goldman Sachs. Private power plants could help stabilize that impact by reducing the burden on the grid. However, an expert quoted by The Washington Post worries that a boom in private energy generation will drive up electricity prices by boosting demand for generation equipment and expertise.
- More gas-fired power plants mean more greenhouse gases in the atmosphere, which are driving climate change. Although big AI companies work hard to use renewable energy and offset greenhouse-gas emissions, the pace of building makes fossil fuels expedient. While public announcements of private-power projects have emphasized renewable, nuclear, or hydrogen power, “the equipment actually being installed in 2025 and 2026 is almost entirely gas-fired,” Cleanview writes.
We’re thinking: Until recently, the cloud-computing leaders have leaned heavily on renewable energy sources such as wind and solar power, sometimes with an assist from batteries. Their move toward gas-fired power plants is an unfortunate reversal of the effort to remain carbon-neutral.
Lightning-Fast Diffusion Learning
Research shows that diffusion image generators can train somewhat faster if they learn to reconstruct embeddings from a pretrained encoder that’s built for vision tasks like classification, segmentation, and retrieval — not image generation. Recent work shows they can train dramatically faster if the diffusion model learns to reconstruct a smaller version of these embeddings.
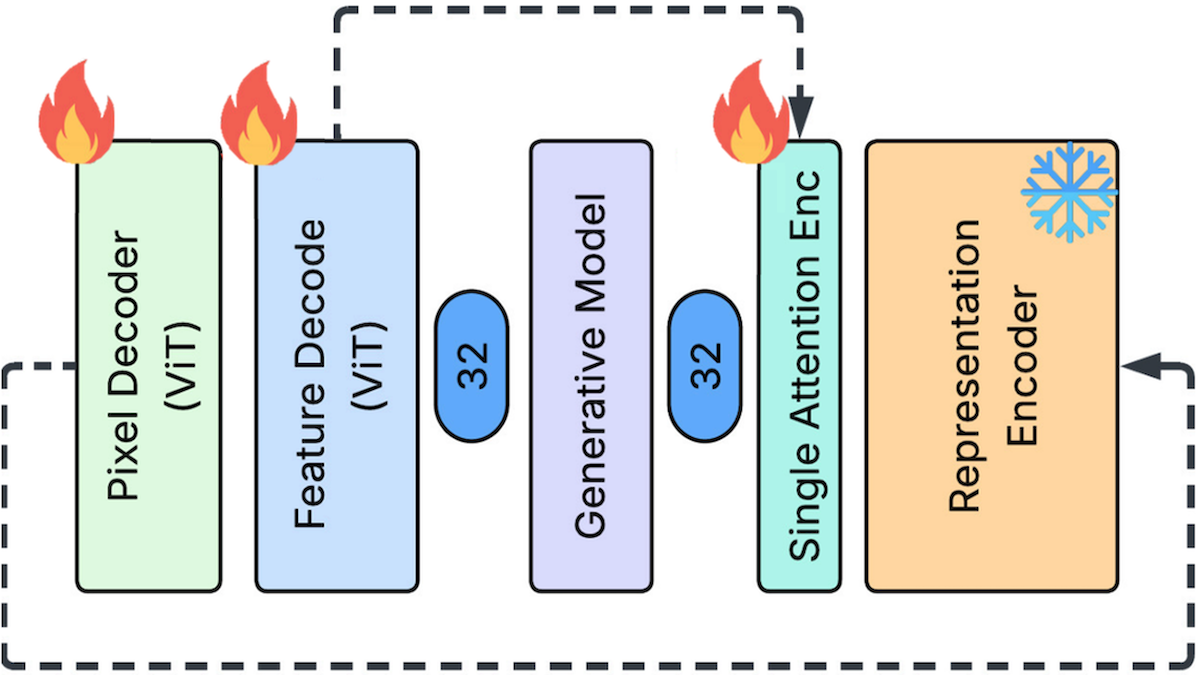
What’s new: Yuan Gao, Chen Chen, Tianrong Chen, and Jiatao Gu at Apple proposed Feature Auto-Encoder (FAE), a diffusion image generator that learned to reconstruct embeddings produced by the vision encoder DINOv2. Where earlier work bogged down on the large size of DINOv2’s embeddings, FAE learned to shrink them before reconstructing them.
Key insight: Latent diffusion models, which remove noise from embeddings that a decoder then turns into images, produce better images from larger embeddings. Embeddings produced by vision encoders such as DINOv2 and SigLIP fit the bill: They’re large and semantically rich. This approach not only improves the output, it potentially accelerates training because the image generator takes advantage of the vision encoder’s pretraining. On the other hand, processing larger embeddings requires a larger architecture and significantly more training, which counteracts much of the speed-up. A solution is to shrink the vision encoder’s embeddings using a second, smaller encoder. The diffusion model can learn to remove noise from this smaller embedding, which requires less training. Then decoders can expand the embedding to its original embedding space, restoring the benefits of the larger embedding, and ultimately produce an image.
How it works: At inference, FAE works like this: Given noise and an ImageNet class or text embedding, SiT (a latent diffusion model) generates a shrunken image embedding. Given that embedding, an embedding decoder produces a full-size embedding, from which an image decoder produces an image. The authors trained two separate FAE systems to generate images from input text labels (using ImageNet at 256x256-pixel resolution) and text descriptions (using CC12M.)
- During training, FAE needed targets to learn to generate the full-size and shrunken embeddings. Given an image, DINOv2 produced a full-size embedding. Given the full-size embedding, a small encoder (a single attention layer) produced the shrunken embedding. Given the shrunken embedding, an embedding decoder expanded it to full size.
- Given the expanded embedding, an image decoder learned to produce an image. It used three loss terms: (i) a reconstruction loss that minimized the difference between predicted and ground-truth pixels; (ii) a perceptual loss in which an unidentified model embedded both a predicted image and ground truth, and the loss term minimized the distance between them; and (iii) an adversarial loss in which an unidentified discriminator classified predicted images and ground truth, and the loss term trained the image decoder to fool it.
- Given a noisy version of a shrunken embedding plus an ImageNet class or text embedding produced by a pretrained SigLIP 2), SiT learned to remove the noise.
Results: FAE performed comparably to state-of-the-art diffusion models while training faster.
- Generating ImageNet images from labels, FAE (675 million parameters) achieved 1.29 FID (a measure of the difference between Inception-V3’s embeddings of an original image and a generated version, lower is better) after training for 800 epochs. This was better than RAE (676 million parameters), a diffusion image generator that learned to reconstruct DINOv2 embeddings without shrinking them. RAE achieved 1.41 FID after 800 epochs. FAE reached 1.41 FID after around seven times faster, in 110 epochs.
- Generating images from text descriptions, FAE (1.1 billion parameters) achieved 6.9 FID on MS COCO. This performance was similar to Re-Imagen (3.2 billion parameters), which reached 6.88 FID after training on roughly four times more training data.
Why it matters: Encoders trained for vision tasks have different knowledge than encoders trained for image generation. That knowledge can help to generate better images, but it resides in bigger embeddings that require more processing power to handle. Shrinking them makes this knowledge available to image generators in a more practical way, making it possible to generate high-quality images in much less time.
We’re thinking: This work produces better images in less training time not by getting better at removing noise, but by removing noise from a richer embedding space.