
Dear friends,
I’m thrilled to announce Context Hub, a new tool to give to your coding agents the API documentation they need to write correct code. If you’re building AI systems using modern technologies, your coding agent will often use outdated APIs, hallucinate parameters, or not even know about the tool it should be using. This happens because AI tools are rapidly evolving, and coding agents were trained on old data that does not reflect the latest tools. Context Hub, which is designed for your coding agent to use (not for you to use!) provides the context it needs. It also accepts automatic agentic feedback to help your coding agents improve over time.
For example, Claude Opus 4.6, possibly the best coding model currently, has a knowledge cutoff date of May 2025. When I ask it to write code to call OpenAI's GPT-5.2, it uses the older OpenAI chat completions API (client.chat.completions.create) rather than the newer responses API (client.responses.create) that OpenAI recommends. Even though the newer API is a year old, there's a lot more data that Opus was trained on that uses the older interface. It also has no idea about the existence of Nano Banana, which was released in August 2025. More generally, I’ve seen coding models fail to make correct API calls to Gemini and many database services (even popular ones, when I use less common parameter choices), or just not know about a particular tool I want.
Consequently, I’ve found myself often writing documentation in Markdown (with help from AI and web search) to give to my coding agent information on how to use different services. In lieu of every developer doing this manually for every service they want to use, over a weekend, Rohit Prsad and I got together to develop an open context management system for giving coding agents the context they need. I’m also grateful to Xin Ye and Neil Thomas for helping with this project.
I encourage you to install Context Hub (chub for short) using npm, and run it to get a sense of its output:
npm install -g @aisuite/chub
chub search openai # find what's available
chub get openai/chat --lang py # fetch current docs

To get your coding agent to use chub, either prompt it (e.g., "Use the CLI command chub to get the latest API documentation for calling OpenAI. Run 'chub help' to understand how it works."), or give it an agent skill to use chub automatically, by using SKILL.md, and ideally prompt your agent to remember to use it. (If you are using Claude Code, create the directory ~/.claude/skills/get-api-docs and put this file there).
Chub is built to enable agents to improve over time. For example, if an agent finds that the documentation for a tool is incomplete but discovers a workaround, it can save a note so as not to have to rediscover it from scratch next time.
Alongside the explosive growth of OpenClaw, we’ve seen the remarkable rise of the social network Moltbook for agents, where agents share information and debate with each other. Motivated by this, we plan to evolve chub toward letting different agents share information about what they discover about different tools and where documentation might contain bugs. This is not yet implemented, but it will be exciting to see a community of coding agents help each other!
We’ve populated chub with an initial set of documentation for some of the most popular tools, like common LLM providers, databases, payment processors, identity management solutions, messaging platforms, and so on. You can see the current list here. If you’re a provider of a popular agent tool, please consider contributing documentation. I hope our community can collectively improve Context Hub for everyone.
Keep building!
Andrew
A MESSAGE FROM DEEPLEARNING.AI

Now available: “Build and Train an LLM with JAX,” made in collaboration with Google. Train a 20 million-parameter, MiniGPT-style language model using JAX. You’ll work through the full LLM training workflow: implementing the architecture, preprocessing training data, managing checkpoints, and running inference through a chat interface. Enroll now
News

Nano Banana 2 Ups Performance/Price
Google launched a cheaper, faster successor to its flagship image generator, delivering greater interactivity at roughly half the price.
What’s new: Google launched Nano Banana 2 (formally designated Gemini 3.1 Flash Image), an image-generation system that takes advantage of Gemini 3 Flash’s speed and strengths in language and reasoning. It’s around four times faster and costs roughly half as much per image as its predecessor Nano Banana Pro.
- Input/output: Text and images in (up to 1 million tokens), images out (up to 4,000 tokens; 512x512, 1024x1024, 2048x2048, or 4096x4096 pixel resolutions; 14 aspect ratios; 4 seconds to 6 seconds per image)
- Architecture: Mixture-of-experts transformer based on Gemini 3 Flash, undisclosed rendering model
- Features: Search (text and image), two levels of reasoning (minimal or high), multilingual text rendering, character and object consistency for up to five characters and 14 objects across multiple generated images, output marked with invisible SynthID watermark and C2PA Content Credentials that record how and when images were generated
- Performance: Leads Arena.ai text-to-image leaderboard of human preference, ranks second and third on Artificial Analysis Text to Image and Image Editing arena-style leaderboards after GPT Image 1.5 and Nano Banana Pro
- Availability: Free (with limits) via Gemini app, Google Ads, Google Antigravity, and Flow; API input $0.50 per 1 million tokens, output $0.045 (512x512 pixel resolution), $0.067 (1024x1024 pixel resolution), $0.101 (2048x2048 pixel resolution), and $0.151 (4096x4096 pixel resolution) per image; image search free for the first 5,000 queries per month, $14 per 1,000 additional queries
- Undisclosed: Architecture details, parameter count, training data and methods, rendering model
How it works: Google disclosed few details about how it built Nano Banana 2 beyond stating that it is “based on” Gemini 3 Flash. Capabilities such as grounding in web search, reasoning, and high-resolution output essentially match those of the previous version Nano Banana Pro. However, the new system is faster, which makes it easier to refine the output iteratively and sequentially. Some users reported that it renders text more accurately.
Performance: Nano Banana 2 ranks among the top three image generators on independent leaderboards.
- On Arena.ai’s text-to-image leaderboard (a head-to-head comparison that ranks systems by human preference), Nano Banana 2 leads (1,280 Elo), ahead of GPT Image 1.5 (1,248) and Nano Banana Pro (1,238). On Arena.ai’s image edit leaderboard, Nano Banana 2 (with web search enabled) places second (1,401 Elo, preliminary results) behind OpenAI’s GPT Image (1,407 Elo) and ahead of Nano Banana Pro (1,398 Elo). However, Nano Banana 2’s score is preliminary (around 3,000 votes), while GPT Image 1.5’s score is well established (around 50,000 votes).
- On the Artificial Analysis text-to-image leaderboard (also a head-to-head comparison that ranks systems by human preference), Nano Banana 2 (1,264 Elo) fell behind OpenAI’s GPT Image 1.5 set to high reasoning (1,268 Elo) and ahead of Nano Banana Pro (Elo 1,220). On the Artificial Analysis image editing leaderboard, Nano Banana 2 (1,233 Elo) trailed GPT Image 1.5 set to high reasoning (1,268 Elo) and Nano Banana Pro (1,250 Elo).
Behind the news: Competition in image generation has been fast and furious. Launched in late August 2025, the first version of Nano Banana (officially called Gemini 2.5 Flash Image) attracted over 10 million new users to the Gemini app within weeks. In November, Nano Banana Pro, based on Google’s Gemini 3 Pro vision-language model, topped image-generation leaderboards. OpenAI responded in December with GPT Image 1.5 — a launch that OpenAI accelerated in response to CEO Sam Altman’s “code red” instructions to catch up to Google, according to TechCrunch. Nano Banana 2 nears the top text-to-image position at a price roughly 60 percent lower than that of GPT Image 1.5 set to high quality.
Why it matters: Creative applications like producing marketing materials, product visualization, or storyboards often require many iterations to arrive at a desired composition, lighting, and style. That makes per-image cost and speed important factors. Grounding in web search can reduce the number of attempts needed to get the output right, and halving the cost per image doubles the budget for those that remain.
We’re thinking: Nano Banana keeps ripening!

U.S. Dept. of War Dismisses Anthropic, Embraces OpenAI
OpenAI signed a contract with the U.S. military to provide AI systems that securely process classified information, displacing Anthropic’s Claude. OpenAI negotiated limits on how its technology can be used, but they leave room for interpretation.
What happened: The agreement between OpenAI and the U.S. Department of War came only hours after a week-long standoff between the White House and Anthropic, which wanted to limit military use of its technology for surveillance and autonomous weapons. The standoff ended with a White House ban on doing business with Anthropic. OpenAI CEO Sam Altman later said the hasty contract he had negotiated was a mistake — the parties renegotiated some restrictions around surveillance and autonomous weapons — and made his company look “opportunistic and sloppy.” Anthropic vowed to sue the government for limiting its business without proper reason or authority.
Power struggle: The U.S. military has been expanding its use of large language models from Anthropic, OpenAI, Google, and xAI at least since early 2025, when President Trump directed federal agencies to eliminate obstacles to AI development.
- On January 3, the U.S. military launched an operation against Venezuela in which it used Anthropic’s technology via a cloud platform provided by Palantir, which performs data analytics for military and law-enforcement agencies. Anthropic executives reportedly expressed concern about that use to Palantir, which relayed the conversation to the government. Anthropic later denied it had objected to the Venezuela operation.
- The following week, the Department of War launched a program to experiment with leading AI models in combat, intelligence, and organizational management. The program required AI companies to renegotiate existing contracts.
- In subsequent negotiations, Anthropic stipulated that Claude could not be used in surveillance of U.S. citizens or to operate fully autonomous weapons. The Department of War said it would not tolerate external limitations. Although the department said it did not intend to use Claude for surveillance or autonomous weapons, the only limits it would accept were those required by U.S. law.
- On February 23, xAI and the Department of War reached an agreement to allow the military to use Grok in classified systems for “all lawful uses.”
- The next day, Secretary of Defense Pete Hegseth met with Anthropic CEO Dario Amodei and vowed to designate Anthropic a “supply chain risk to national security” if the company did not agree to relax its restrictions by 5:01 p.m. on Friday. Contractors that supply the U.S. military are barred from doing business with companies that are deemed supply-chain risks. This designation previously had been applied only to non-U.S. companies that posed a risk to national security.
- Within hours, OpenAI, too, signed a contract that allows the Department of War to use its technology “for all lawful purposes” while retaining its own safety guardrails.
- Anthropic continued to negotiate but balked at the language about lawful purposes, since the law has not stopped the government from spying on U.S. citizens in the past. The Department of War said it wanted to analyze unclassified, commercial bulk data on U.S. citizens, including locations and web data. While the U.S. military is prohibited from conducting surveillance on U.S. citizens, it is allowed to aggregate and analyze commercial data.
- On February 27 just before 1:00 p.m. — four hours before the deadline — President Trump posted on Truth Social, a social network owned by the President, directing all federal agencies to stop using Anthropic’s technology within six months. The post threatened “major civil and criminal consequences” if Anthropic did not cooperate, calling Anthropic an “out-of-control, Radical Left AI company run by people who have no idea what the real World is all about.”
- At 5:14 p.m. that day, Hegseth announced on the X social network that he had designated Anthropic a supply-chain risk to national security, forbidding contractors, suppliers, and partners that do business with the United States military from using its technology.
- Subsequently, some non-military U.S. agencies terminated their use of Anthropic products.
- On March 2, OpenAI’s Altman announced that his company’s agreement had been rushed. It was amended, ostensibly to build in limits on uses for surveillance and autonomous weapons, but also leaving substantial ambiguity. The revised contract prohibits uses of OpenAI technology for domestic surveillance of U.S. citizens including via analysis of “commercially acquired personal or identifiable information,” which presumably allows uses of other types of information. It also bars uses to “independently direct autonomous weapons in any case where law, regulation, or Department policy requires human control,” apparently leaving room to use the technology to operate autonomous weapons in other ways.
Behind the news: A number of U.S. laws empower the Department of War to name supply-chain risks to national security. This designation allows the government to exclude such risky companies from either defense contracts or all federal contracts and to disallow other contractors from working with them. The only use of this power in the public record occurred last year, when the Department of War issued an order against Acronis, a Swiss cybersecurity firm that has reported ties to Russia, Lawfare reported. Other laws empower other federal departments to name supply-chain risks. For instance, in 2024 the Department of Commerce designated Kaspersky, a Russian cybersecurity company, a supply-chain risk to federal information systems, in 2020 the Federal Communications Commission labeled the Chinese electronics manufacturers Huawei and ZTE risks to communications supply chains.
Why it matters: AI is rapidly becoming entangled in issues of national security and national identity. The disputes between Anthropic, the White House, and the Department of War, and their implications for OpenAI, xAI, and Google, raise difficult questions about limits on the power of governments to manage warfare and the power of AI companies to set the terms of their models’ use. The Department of War, which would like a free hand to use AI as it sees fit, imposed an unprecedented penalty — which struck many observers as a harsh retaliation against Anthropic’s firm stand — and Anthropic showed faith that courts will rule the punishment invalid.
We’re thinking: The U.S. Congress is responsible for making rules that protect the Americans from mass surveillance and autonomous weapons. Exercising that responsibility could head off conflicts between the government and AI developers. Laws that placed appropriate limits on AI applications would provide clear guidelines to help resolve such power struggles between the military and technology companies.
Management for Agents
Managers need to understand how their subordinates get work done, what resources they require, and what they accomplish. OpenAI’s latest product aims to fulfill this need when the teammates are AI agents.
What’s new: OpenAI announced Frontier, a platform designed to help orchestrate corporate cadres of agents, including building them, sharing information and business context among them, evaluating their performance, and managing their interactions with employees and each other. Cisco and T-Mobile have used the system in pilot projects, and OpenAI is offering it, along with dedicated engineering help, to selected clients including HP, Intuit, and Uber. It plans to make Frontier more widely available in coming months under terms that are not yet disclosed.
How it works: Frontier provides a unified user interface for managing agents regardless of the frameworks and models involved. Administrators can build or import agents, provide access to them, integrate data sources and applications, and manage billing, among other functions. OpenAI revealed little information about the system but shared some key points:
- Each agent has its own identity, permissions, and guardrails, and companies can control which employees or groups can use it.
- Agents can share context including access to data, tools, applications, and information about relevant systems and workflows.
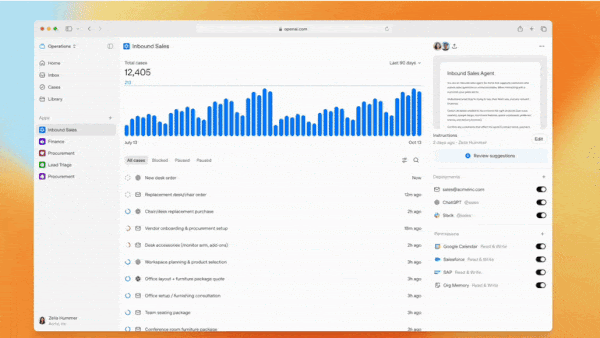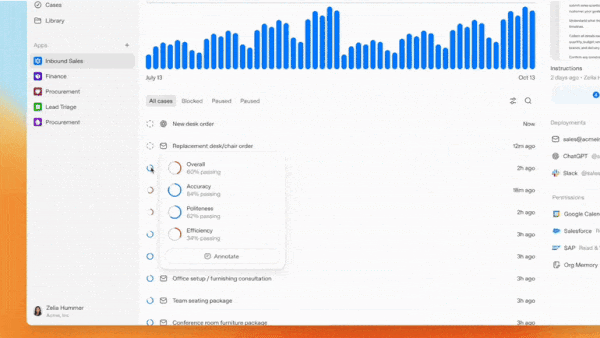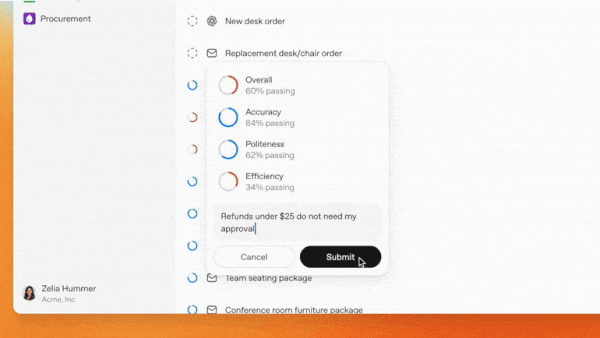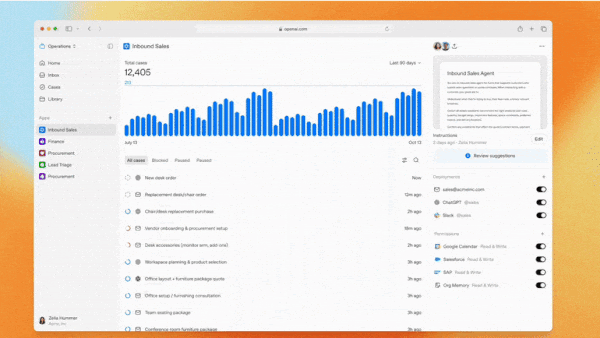
- Frontier evaluates agents’ outputs and provides feedback to improve their performance. Based on promotional illustrations, it appears that users can set evaluation metrics based on ground-truth data, such as accuracy, or model output, for example, using a large language model to measure politeness.
- Agents can “build memories, turning past interactions into useful context,” which implies that agents can improve their performance automatically over time by recalling successful responses to earlier prompts.
Behind the news: Frontier arrives a few months after Microsoft released Agent 365, a similar platform that integrates with Microsoft applications like Word and Excel. Agent 365 focuses more tightly on security and governance, while Frontier offers more features for building, evaluating, and improving agents.
Why it matters: As a company puts more agents to work, the ability to manage them en masse becomes more valuable. For instance, an agent deployed by one group within a company may have broader utility, or agents deployed by disparate groups may duplicate functions or work at cross purposes. A unified control interface may make such opportunities and issues more apparent. The agent-management systems from OpenAI and Microsoft aim to enable teams to manage these activities from a higher level.
We’re thinking: Conceptually, a “human resources” system for agents makes sense. Such systems are in their infancy — as suggested by OpenAI’s limited rollout and provision of engineering help — but they have clear utility that’s likely to grow as companies put more agents to work on their behalf.
Agent Solves Stubborn Math Problems
LLMs have achieved gold-medal performance in math competitions. An agentic system showed strength in mathematical research as well.
What’s new: Tony Feng, Quoc V. Le, Thang Luong, and colleagues at Google introduced Aletheia, an agent that generated, verified, and revised solutions to previously unsolved math problems. Aletheia is an agentic workflow for math research that uses the latest update of Gemini 3 Deep Think, a specialized reasoning mode of the Gemini 3 Pro model for subscribers to the company’s top-tier AI service. Concurrently, Google made Gemini 3 Deep Think more widely available via API.
Gemini 3 Deep Think: Google bills Deep Think as its most advanced reasoning mode, geared toward multi-step tasks in math, science, and engineering. It generates multiple chains of reasoning in parallel, considers them, and revises or combines them to produce final output.
- Input/output: Text, image, video, audio, pdf in (up to 1 million tokens); text out (up to 65,000 tokens)
- Performance: Achieved state of the art on HLE (48.4 percent without tools), ARC-AGI-2 (84.6 percent), Codeforces (3455 Elo), GPQA Diamond (93.8 percent)
- Availability: Via Gemini app with Google AI Ultra subscription ($250/month), via API with early access
- Features: web search, code execution
- Undisclosed: Google has disclosed little information about how it built Gemini 3 Pro and the Deep Think capability
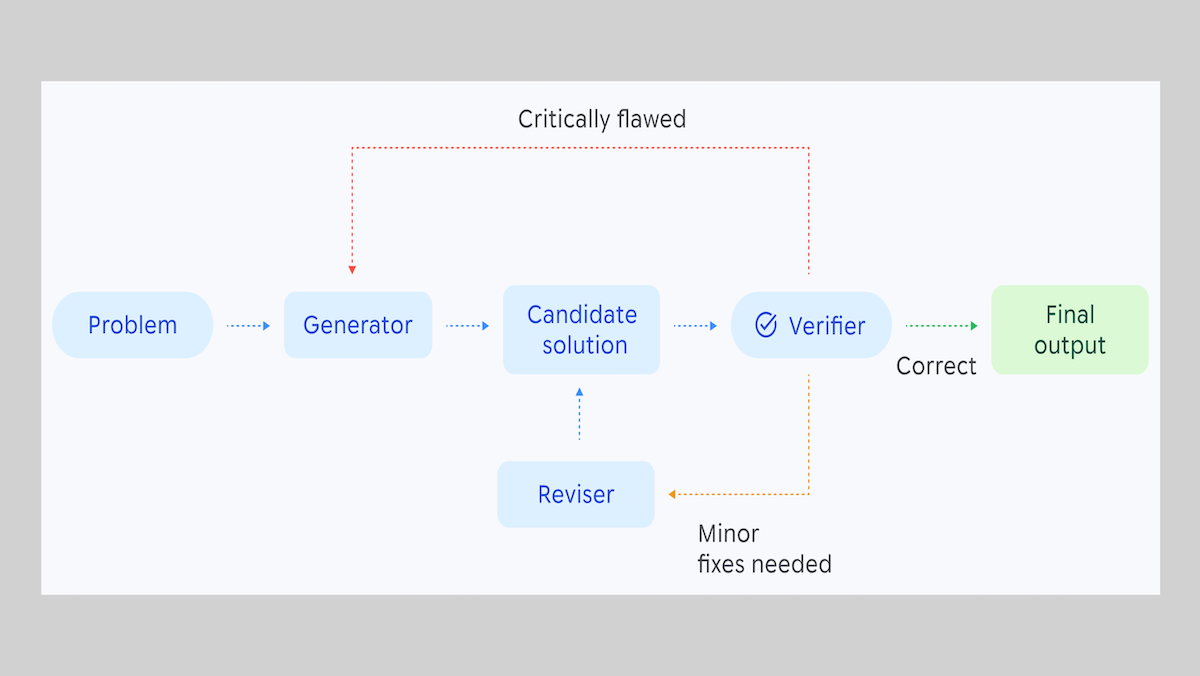
How it works: Aletheia is an agentic workflow with three parts — generator, verifier, and reviser — all powered by Gemini 3 Deep Think.
- Given a problem, the generator produces an initial solution.
- The verifier checks that solution and marks it either as complete, in need of fixes, or critically flawed.
- If the solution needs fixes, the reviser takes the problem and solution, and generates a modified version of the solution, which it feeds back to the verifier.
- If the solution is critically flawed, the generator takes the problem again and generates a new solution.
- The process repeats until the verifier marks a problem as solved or an author-set number of model calls occurs.
Results: Researchers have used Aletheia in six published papers to date: two in which Aletheia did essentially all the work, two in which both humans and Aletheia contributed significantly, and two in which humans did most of the work and Aletheia helped a little. The authors note that Aletheia works well in situations where broad knowledge across subfields of math is helpful, but it doesn’t have as much depth within subfields as a human specialist.
- One of the papers offers four novel solutions to unsolved Erdős problems, a set of difficult-to-solve mathematical conjectures proposed by the mathematician Paul Erdős. Of the remaining 700 unsolved Erdős problems, Aletheia said it found solutions to 212 of them.
- Mathematicians examined the 212 solutions and found them correct or incorrect in 200 cases. (For the other 12, the problem or solution was ambiguous.) Of the 200, 137 (68.5%) were incorrect, 63 (31.5%) were technically correct under some interpretation of the problem, and 13 (6.5%) were correct under the intended interpretation.
- The authors examined the 13 correct answers to evaluate their novelty. The problem had already been solved in 9 of them: Aletheia either identified the solution from existing research or solved a problem that had a solution in existing research.
- The remaining four solutions were novel.
Behind the news: AI-assisted proofs have had limited but real success. In most previous work, researchers used an LLM to help them prove a given theorem, as opposed to building a generalist system like Aletheia. Most similar would be Google’s AlphaEvolve, an agentic system that improved algorithms for scheduling compute usage in a data center and multiplying matrices.
Why it matters: Agentic systems are becoming useful mathematical tools that can work with mathematicians to help generate new methods, roadmaps, and the like. If, like Aletheia, an agent’s strength is its breadth of knowledge, it may accelerate research into problems that touch on knowledge from many subfields, while human specialists continue to dive into their favorite fields.
We’re thinking: Erdős proposed nearly 1,200 problems between the early 1930s and his death in 1996. Fewer than 500 have been solved, but AI models have helped to solve around 100 of them in the past six months alone!