
OpenAI has been making deals with publishers to gain access to high-quality training data. It added Financial Times to the list.
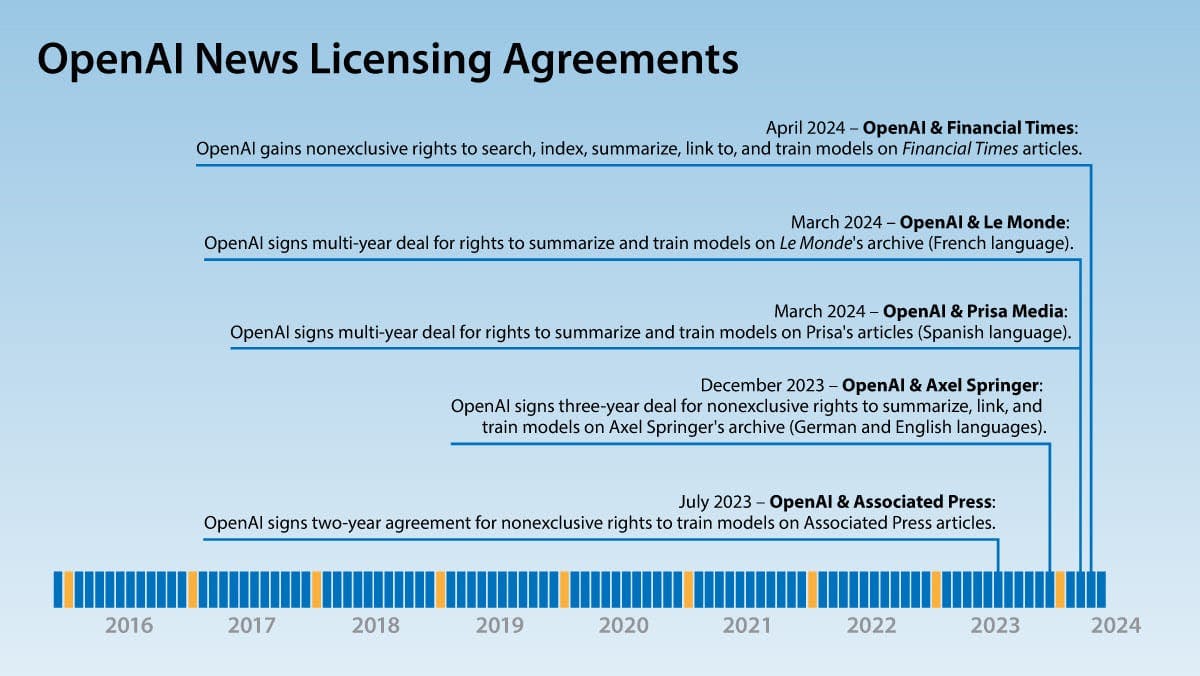
What’s new: OpenAI licensed the archive of business news owned by Financial Times (FT) for an undisclosed sum. The agreement lets OpenAI train its models on the publisher’s articles and deliver information gleaned from them. This is OpenAI’s fifth such agreement with major news publishers in the past year.
How it works: Although the parties didn’t disclose the length of their agreement, OpenAI’s other news licensing deals will end within a few years. The limited commitment suggests that these arrangements are experimental rather than strategic. The deal includes articles behind the publisher’s paywall; that is, not freely available on the open internet. This enables OpenAI to train its models on material that competitors may not have. Other deals have given OpenAI exclusive access, shutting competitors out.
- The deal with FT gives OpenAI nonexclusive rights to search, index, and train its models on the publisher’s articles, including articles behind its paywall. It also lets OpenAI enable ChatGPT to cite, summarize, and link to the publishers’ works. The parties called the deal a “strategic partnership” as well as a licensing agreement, although it’s unclear whether OpenAI will share technology or data with FT.
- In March, OpenAI announced multi-year agreements with French newspaper Le Monde and Prisa Media (Spanish owner of the newspapers El País, Diario AS, and Cinco Días). The agreements give OpenAI rights to summarize and train AI models on their articles and make the publishers, respectively, OpenAI’s exclusive providers of French- and Spanish-language news.
- In December 2023, OpenAI signed a three-year, nonexclusive deal with German publisher Axel Springer, owner of German-language newspapers Bild and Die Welt as well as English-language websites Politico and Business Insider. The deal allows OpenAI to train on, summarize, and link to Axel Springer’s articles, including paywalled content, and makes the publisher OpenAI’s exclusive supplier of German-language news. It was worth “tens of millions of euros,” according to Bloomberg.
- In July 2023, OpenAI gained nonexclusive rights for two years to train its models on some of the text of the Associated Press (AP) archive of news articles, which freely is available on the open web. In return, AP received undisclosed access to OpenAI’s “technology and product expertise.” Unlike the other agreements, the deal with AP (which does not have a paywall) does not grant OpenAI specific rights to summarize or link to AP’s stories.
Behind the news: Archives of news articles may be handy if OpenAI proceeds with a rumored search service reported by in February by The Information. Licensing is a way to get such material that is unambiguously legal. Although AI researchers commonly scrape data from the web and use it for training models without obtaining licenses for copyrighted works, whether a license is required to train AI models on works under copyright in the U.S. has yet to be determined. Copyright owners lately have challenged this practice in court. In December 2023, The New York Times sued OpenAI and Microsoft, claiming that OpenAI infringed its copyrights by training models on its articles. In April 2024, eight U.S. newspapers owned by Alden Global Capital, a hedge fund, filed a lawsuit against the same defendants on similar grounds. Licensing material from publishers gives OpenAI access to their works while offering them incentives to negotiate rather than sue.
Why it matters: AI developers need huge amounts of media to train larger and larger models. News publishers have huge archives with high-quality text, relatively well written and fact-checked, that’s relevant to current events of interest to a broad audience. Licensing those archives gives developers access to what they need without incurring legal risk. Furthermore, making news archives available for retrieval augmented generation makes chatbots more capable and reliable.
We’re thinking: We support efforts to clarify the legal status of training AI models on data scraped from the web. It makes sense to treat the open web pages and paywalled content differently, but we advocate that AI models be free to learn from the open internet just as humans can.