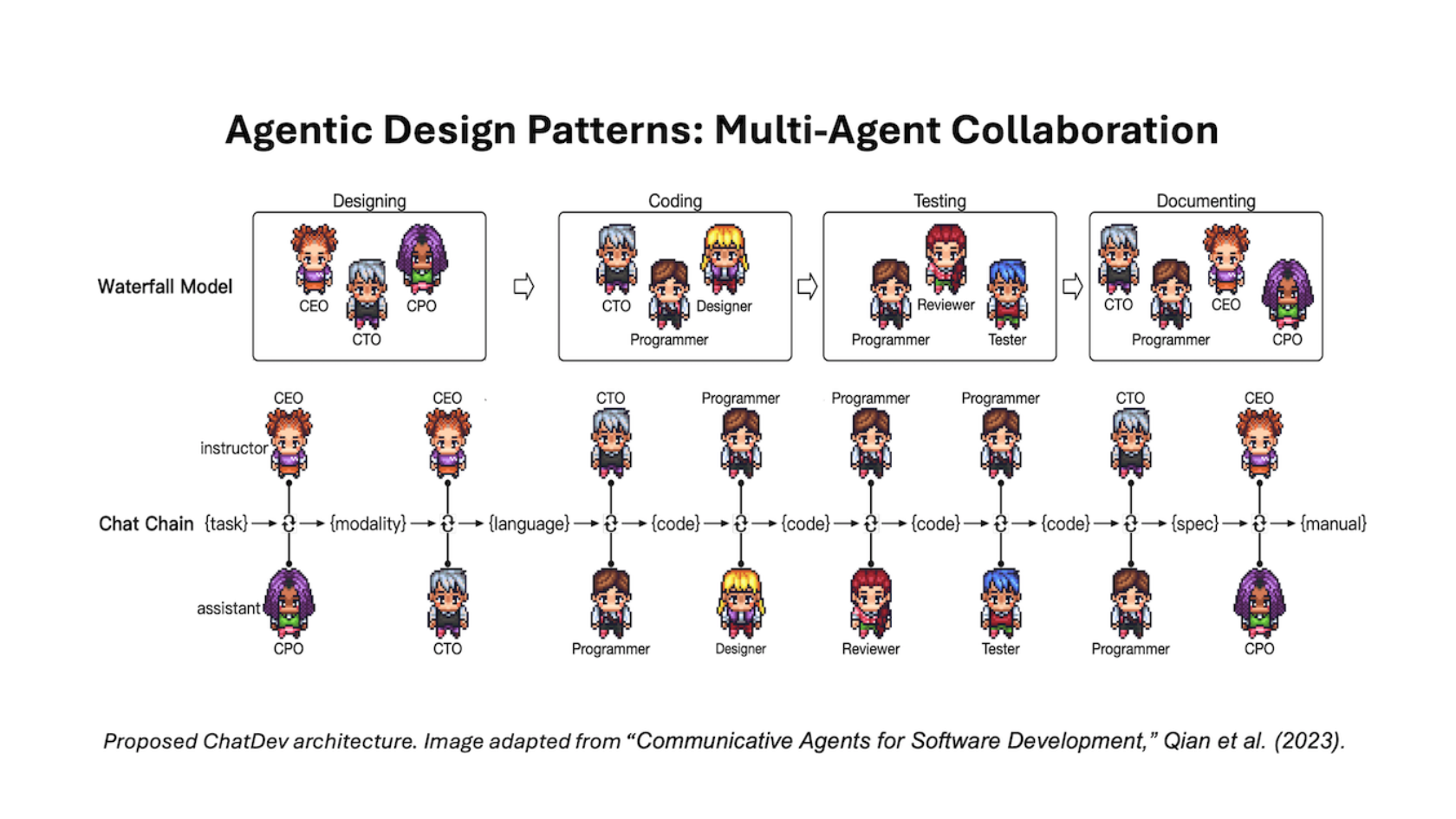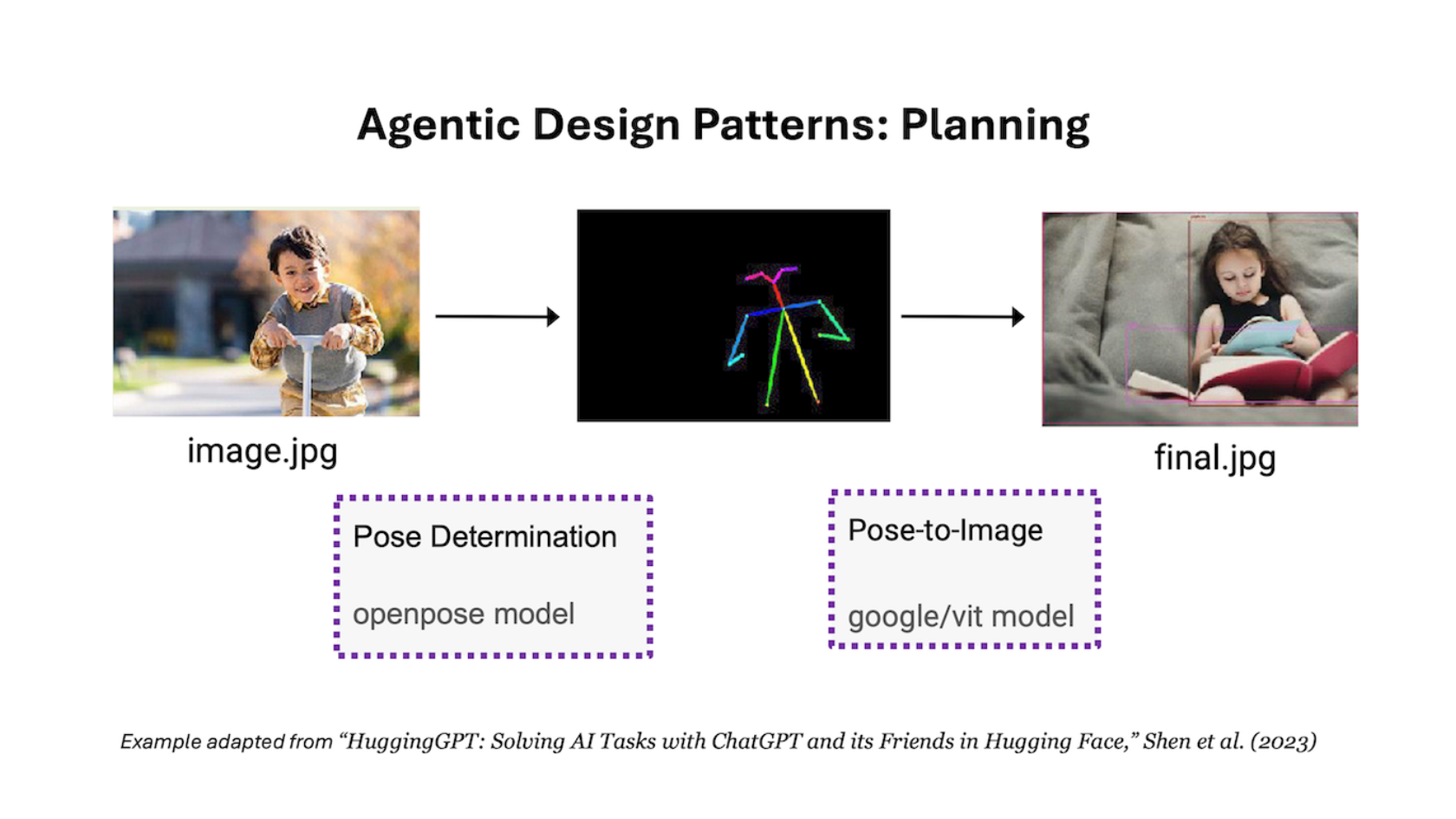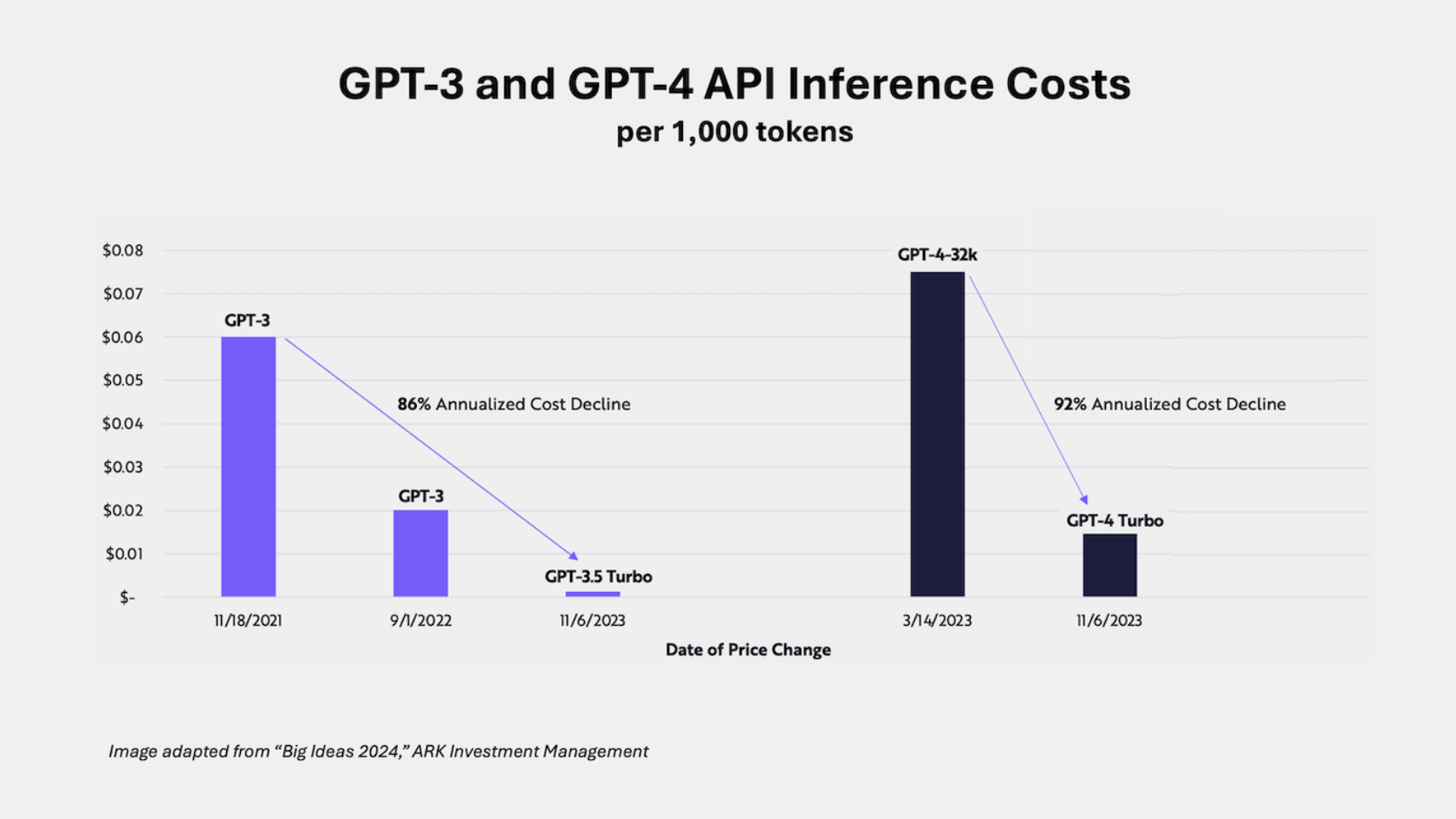
Apr 24, 2024
Pop Song Generators, 3D Mesh Generators, Real-World Benchmarks, AI for Manufacturing
The Batch AI News and Insights: Much has been said about many companies’ desire for more compute (as well as data) to train larger foundation models.
Get the latest AI news, courses, events, and insights from Andrew Ng and other AI leaders.
Join over 7 million people learning how to use and build AI
Build a foundation of machine learning and AI skills, and understand how to apply them in the real world.

How to Build Your Career in AI
A practical roadmap to building your career in AI from AI pioneer Andrew Ng

Machine Learning Yearning
An introductory book about developing ML algorithms.

A Complete Guide to Natural Language Processing
A comprehensive guide covering all you need to know about NLP.