Apr 17, 2024
AI Agents With Low/No Code, Hallucinations Create Security Holes, Tuning for RAG Performance, GPT Store's Lax Moderation
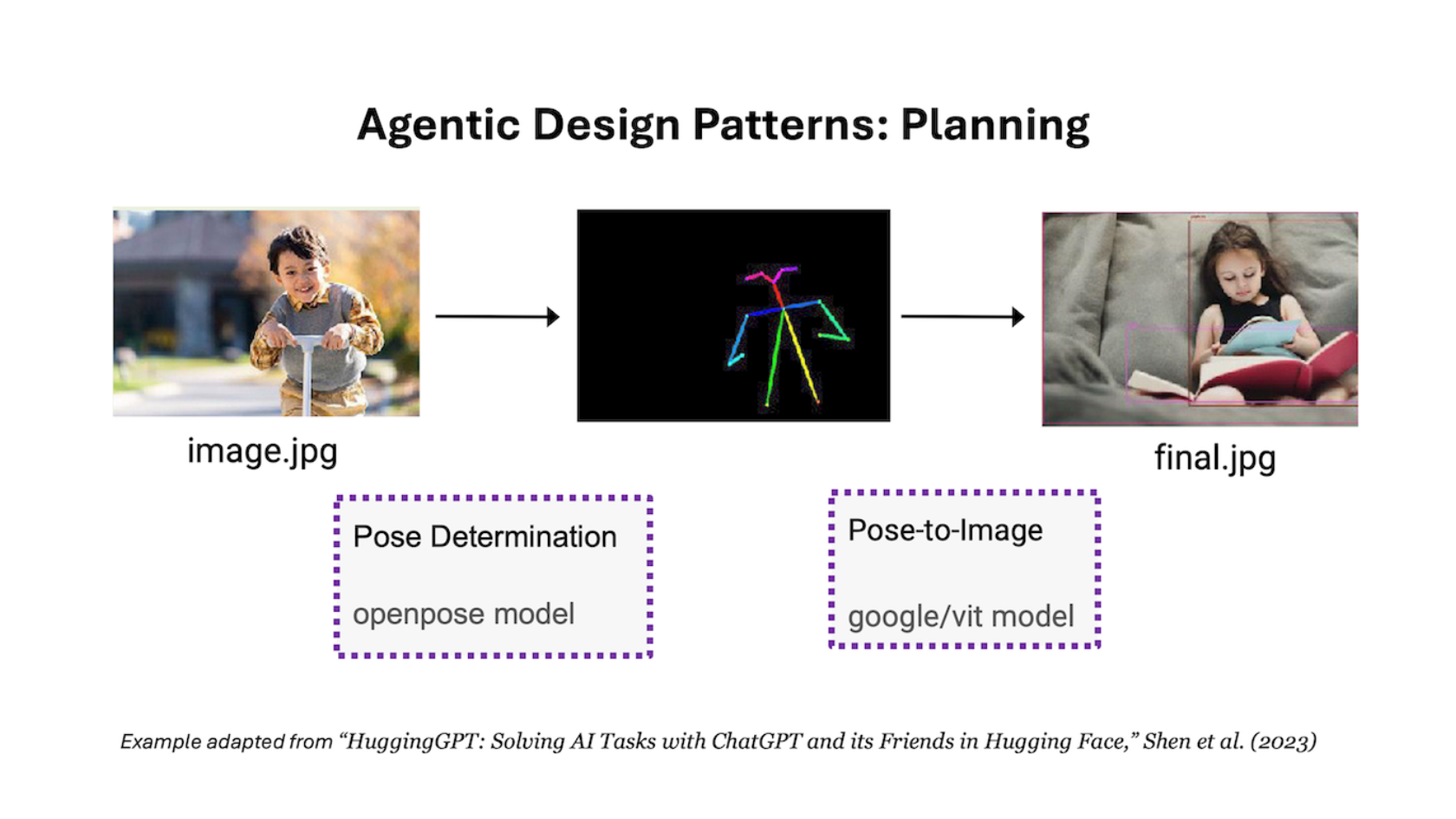
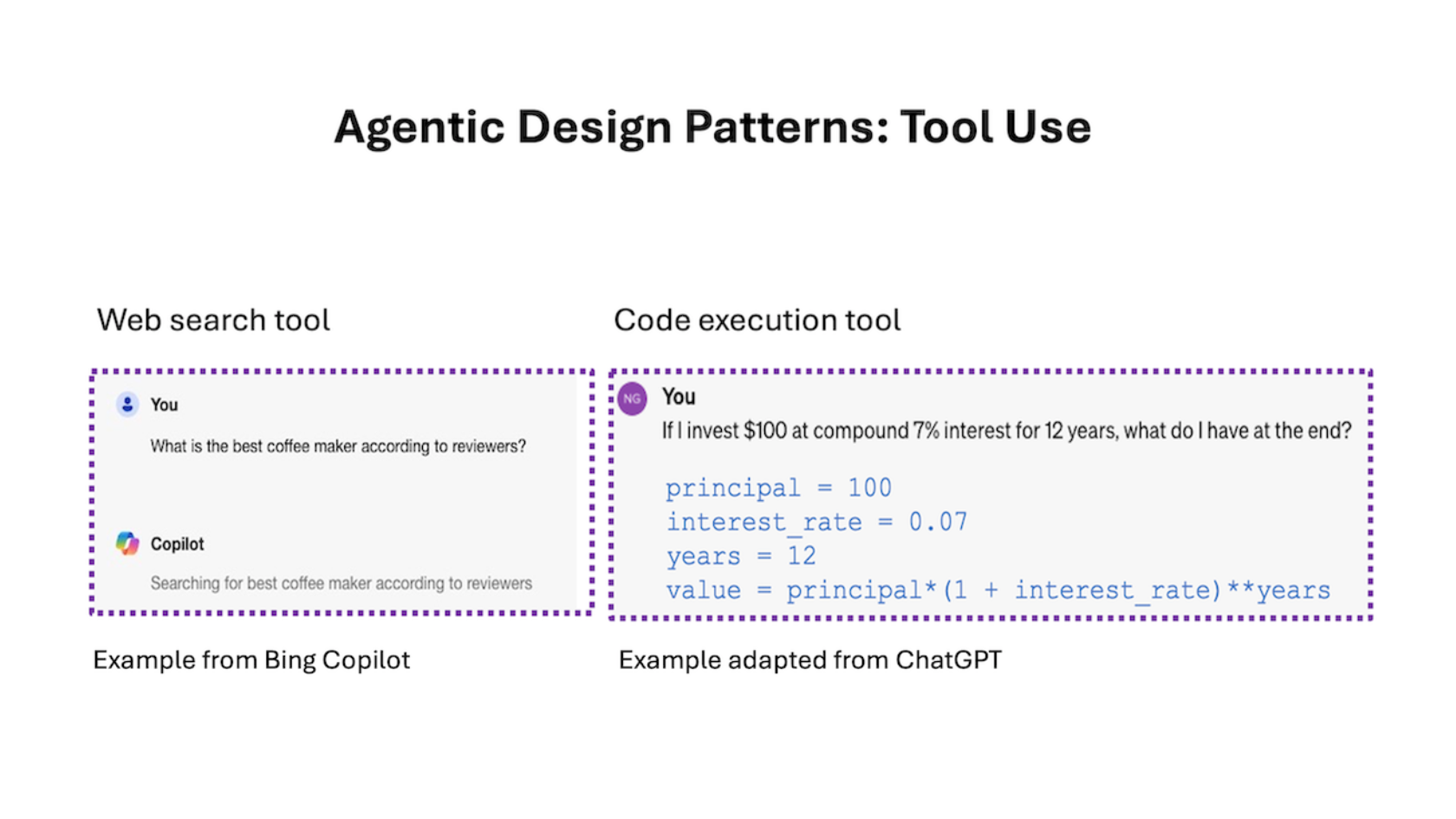
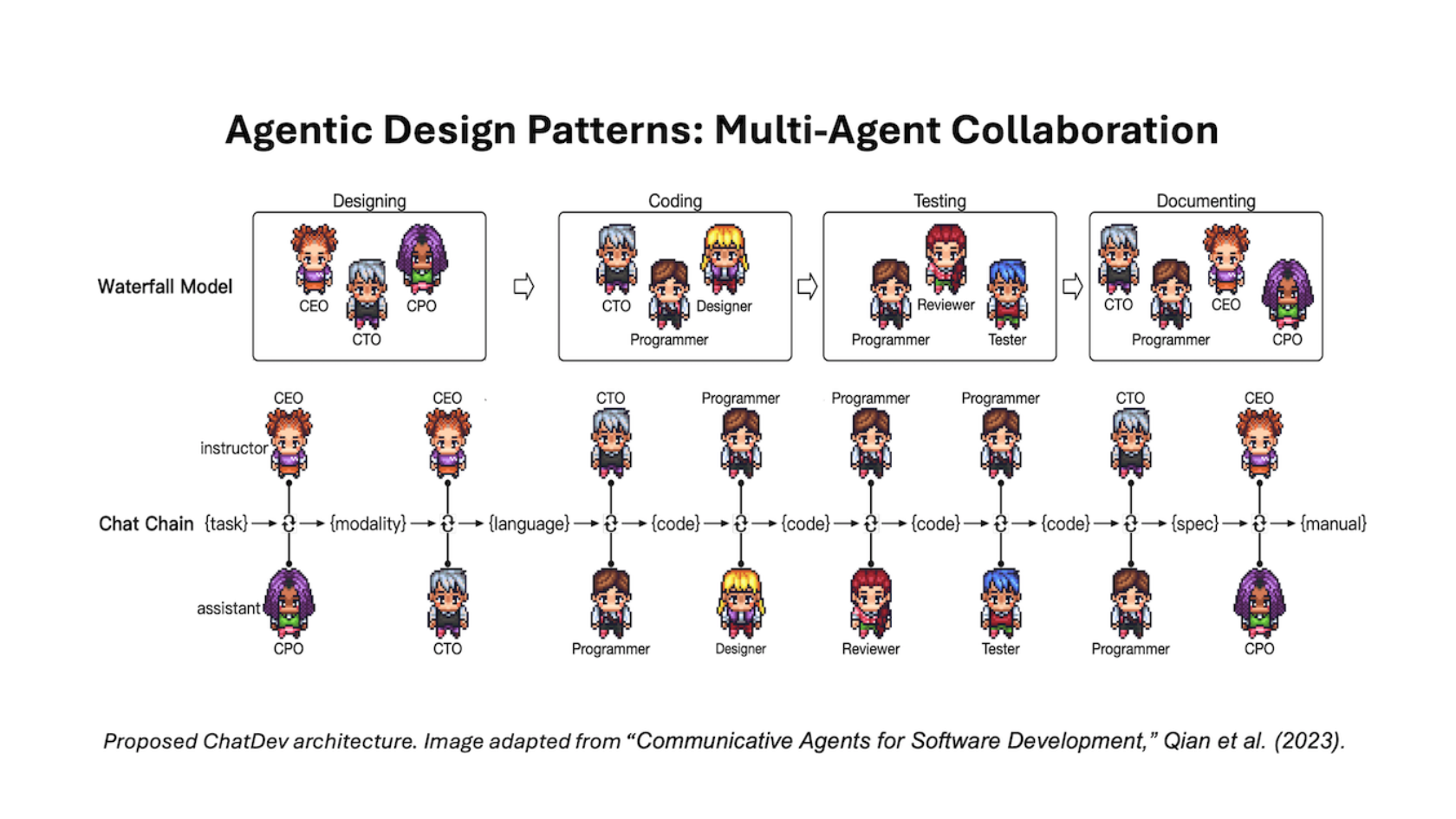
The Batch AI News and Insights: Multi-agent collaboration is the last of the four key AI agentic design patterns that I’ve described in recent letters. Given a complex task like writing software, a multi-agent approach would break...